개요
1. Django에서 DB의 data를 추출해서 DataFrame으로 만든다.
2. 만들어진 DataFrame을 한글파일명을 가진 csv파일로 변환해서 내보낸다.
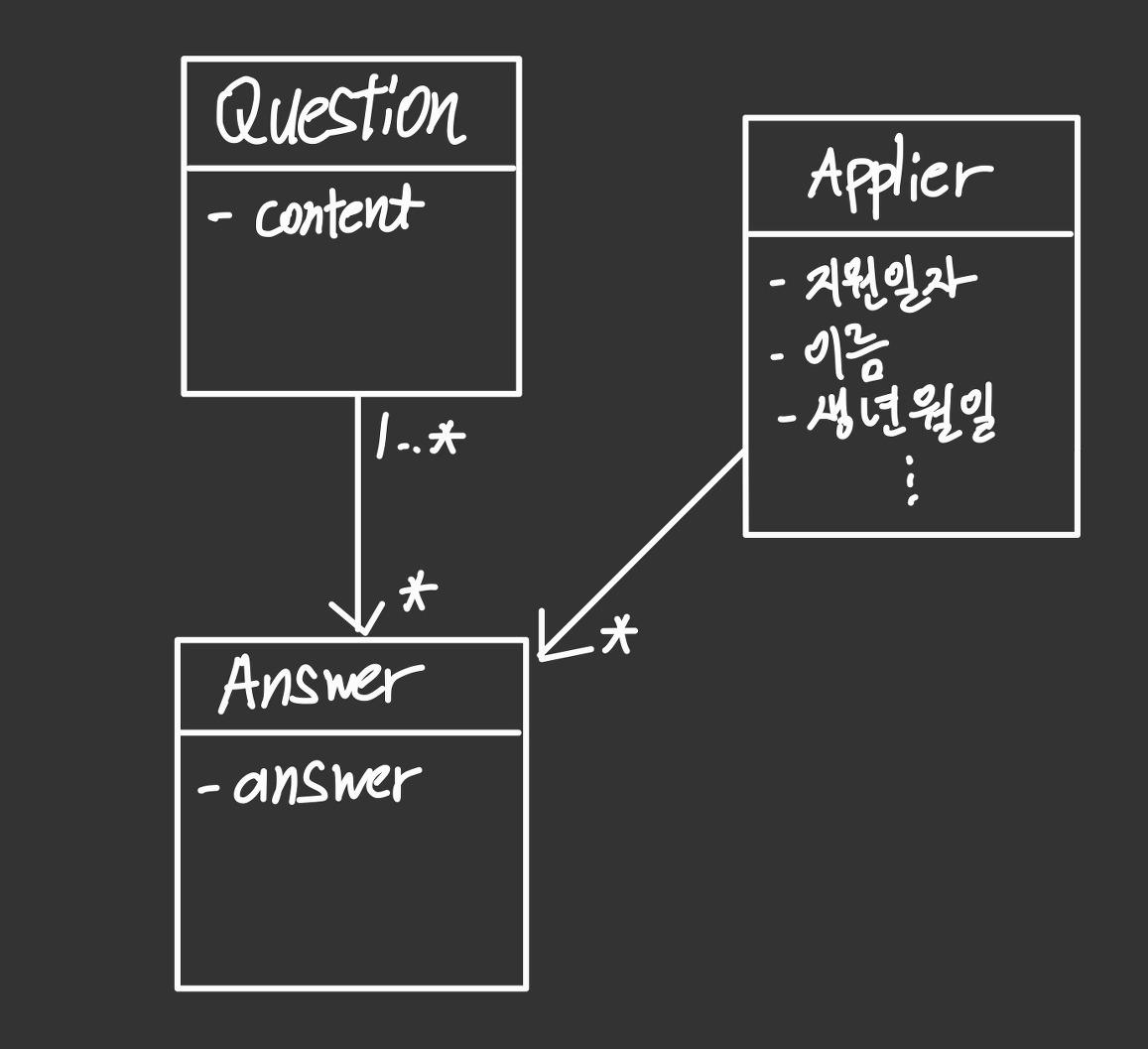
dataframe to csv를 수행할 정보에 대해 아주 간단하게 요약한 class 다이어그램이다.
Question이 다수 있을 것이고, 지원자들은 특정 Question에 대해서 Answer를 남길 것이다.
| 지원일자 | 이름 | 생년월일 | Question1.content | Question2.content | ... | |
| 0 | 2021-10-11 23:56:23 | 김 | 1998.09.09 | ~~ | ** | ... |
| 1 | 2021-10-13 13:54:11 | 이 | 1999.09.09 | %% | ## | .... |
| 2 | 2021-10-14 08:10:45 | 박 | 2000.09.09 | && | @@ | ..... |
최종 DataFrame 및 csv 형식
위의 양식처럼 dataframe을 만들고 csv로 download할 수 있는 기능을 만들어보자
## apis.py
import urllib
from rest_framework.views import Response, status, APIView
from django.http.response import HttpResponse
from survey.models import *
from survey.services import createApplierDF, addApplierDF
...
class ApplierCSVApi(APIView):
def get(self, request, *args, **kwargs):
"""
해당 설문지 응답 리스트 csv파일로 다운로드
"""
survey_id = kwargs["survey_id"]
survey = Survey.objects.get(pk=survey_id)
question_list = Question.objects.filter(
survey=survey
).\
order_by('order')
applierDf = createApplierDF(question_list)
applier_query = Applier.objects.prefetch_related(
'answer',
'answer__question'
).\
filter(
survey=survey
).order_by('apply_date')
applierDf = addApplierDF(applier_query, applierDf)
response = HttpResponse(content_type='text/csv', charset="utf-8")
filename = "{}.csv".format("".join(survey.title.split()))
filename = urllib.parse.quote(filename.encode('utf-8'))
response['Content-Disposition'] = "attachment; filename*=utf-8''{}".format(filename)
applierDf.to_csv(path_or_buf=response)
return response
...## services.py
import pandas as pd
from survey.models import Answer
def createApplierDF(question_list):
columns = ["지원일자", "이름", "성별", "생년월일", "전화번호"]
for question in question_list:
columns.append(question.content)
columns.append("선발여부")
df = pd.DataFrame(columns=columns)
return df
def addApplierDF(applier_query, df):
for applier in applier_query:
newdata = {}
newdata["지원일자"]=applier.apply_date.strftime('%Y-%m-%d %H:%M:%S')
newdata["이름"]=applier.name
newdata["성별"]=applier.gender
newdata["생년월일"]=applier.birth
newdata["전화번호"]=applier.phone
for answer in applier.answer.all():
newdata[answer.question.content]=answer.answer
newdata["선발여부"]=applier.is_picked
df = df.append(newdata, ignore_index=True)
return df
- url에서 survey_id를 추출해서 클라이언트가 원하는 설문지를 알아낸다.
- 설문지와 연관된 Question을 모두 가져온다. (Select * from Question where survey=survey orber by 'order')
- Question을 통해서 DaraFrame의 colums를 설정해준다.
- 현재 설문지에 지원한 지원자를 모두 추려낸다.
prefetch_related를 통해서 찾고자하는 지원자들이 작성한 answer들을 찾고, answer와 연관된 Question을 찾는다. - 현재 설문지에 지원한 지원자에 대한 답변들이 모두 담긴 쿼리문을 반복하면서 DataFrame의 한 행씩 채워나간다.
- 위 표와 같이 DataFrame이 반환되고, 현재 설문지의 title을 파일명으로해서 파일을 다운로드한다.
DataFrame을 만들기는 어렵지 않았다. 그런데 csv파일로 내려받을 때 파일명을 영어로 해주지 않으면 제대로 내려받아지지 않는 현상때문에 api를 완성하기까지 오래걸리게 되었다.
response = HttpResponse(content_type='text/csv', charset="utf-8")
filename = "{}.csv".format("".join(survey.title.split()))
filename = urllib.parse.quote(filename.encode('utf-8'))
response['Content-Disposition'] = "attachment; filename*=utf-8''{}".format(filename)
applierDf.to_csv(path_or_buf=response)
return response
먼저 response 변수에 HttpResponse 객체를 담아준다.
우리는 csv 형식으로 내려받을 예정이므로 content_type을 text/csv로 맞춰준다. 만약 excel로 내려받고 싶다면 content_type='application/vnd.ms-excel' 로 설정해주면 된다.
** 주의할 점은 response의 charset="utf-8"을 반드시 붙여줘야 한다는 것이다.
utf-8로 설정해주지 않으면 csv파일 내부의 한글들이 모두 깨지는 상황이 발생할 것이다.
그다음 survey.title의 띄어쓰기를 없애고, urllib을 사용해서 filename을 utf-8로 인코딩 해주었다.
이 작업은 아래 reponse["Content-Disposition"]을 설정해 줄 때 filename을 한글로 설정하기 위한 작업이다.
reponse["Content-Disposition"] 에서 attachment; 의 뜻은 파일을 다운로드가 가능하도록 내려준다는 뜻이다.
그 옆 문장은 filename을 utf-8로 인코딩해서 보여준다는 뜻이다.
마지막으로, 만든 DataFrame을 csv로 변환해서 response로 보내준다. path_or_buf 인자를 설정해줌으로써 내부에 파일로 저장할지, buffer로 내려줄지를 결정할 수 있다.
'Back-End > Django' 카테고리의 다른 글
| [Django] Nested Serializer - Create (0) | 2021.12.31 |
|---|---|
| [Django] django-debug-toolbar 안보임 오류 해결 (0) | 2021.12.17 |
| [Djnago] Django 이메일 인증하기(Thread) (0) | 2021.10.27 |
| [Django] Django Api 인증, 권한 설정 (0) | 2021.10.27 |
| [Django] PROJECT 홈페이지 (유저 모델, 쿼리 최적화) (2) | 2021.10.24 |