![[운영체제] Ch3. 프로세스](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FW6v2I%2FbtrsA6zRLgI%2FKqs1oRmnQgakD0fel2gDn0%2Fimg.jpg)

공룡책(운영체제)을 읽고 정리한 글입니다.
프로세스가 무엇인지, 운영체제에서 어떻게 표현되는지, 어떻게 작동하는지에 대해 알아보자
프로세스 개념
1. 프로세스
비공식적으로, 프로세스는 실행 중인 프로그램을 의미한다.
프로세스의 현재 활동 상태는 프로그램 카운터 값과 레지스터의 내용으로 나타낸다.
프로세스의 메모리 배치는 아래 그림과 같다.
- text : 실행 코드
- data : 전역 변수
- heap : 런타임중에 동적으로 할당되는 메모리
- stack : 지역변수
주의할 점은 스택과 힙 영역이 서로의 방향으로 커지더라도 운영체제는 서로 영역을 침범하지 못하도록 해야한다.
프로그램 자체는 프로세스가 아니다. 프로그램은 명령어 리스트를 내용으로 하는디스크에 저장된 실행파일에 불과하다(수동적). 이와 반대로 프로세스는 다음에 실행할 명령어를 정하는 프로그램 카운터와 같은 자원을 가지고 있는 능동적인 존재이다.
즉, 실행 파일이 메모리에 적재될 때, 프로그램이 프로세스가 된다.
두 프로세스들이 동일한 프로그램에 연관될 수도 있다.
예를 들어 웹 브라우저 프로그램의 여러 복사본을 띄우는 경우이다. 이들의 text 영역이 동일할지라도 데이터, 힙, 스택 영역은 다를 수 있다. 따라서 프로세스가 실행되는 과정에서 많은 프로세스가 생성되는것은 당연한 일이 되었다.
그리고 프로세스 자체가 다른 프로세스의 실행 환경이 될 수 있다.
대표적인 예로 JVM이 있다. Java 프로그램은 JVM 환경 안에서 실행된다.
2. 프로세스 상태
프로세스는 실행되면서 상태가 변한다.
- 새로운(new) : 프로세스가 생성 중이다.
- 실행(running) : 명령어들이 실행되고 있다.
- 대기(waiting) : 프로세스가 어떤 이벤트가 일어나기를 기다린다.
- 준비(ready) : 프로세스가 처리기에 할당되기를 기다린다.
- 종료(terminated) : 프로세스의 실행이 종료되었다.
3. 프로세스 제어 블록
각 프로세스는 운영체제에서 프로세스 제어 블록(process control block, PCB)(==태스크 제어 블록)에 의해 표현된다.
프로세스 제어 블록은 다음과 같은 것들을 포함한다.
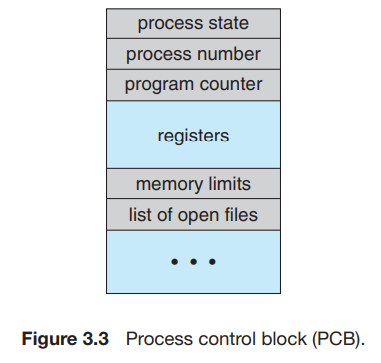
- 프로세스 상태
new, running, ready, waiting, halted(정지) - 프로그램 카운터
프로그램 카운터는 이 프로세스가 다음에 실행할 명령어의 주소를 가리킨다. - CPU 레지스터들
컴퓨터의 구조에 따라 다양한 수와 유형을 가진다.
누산기, 인덱스 레지스터, 스택 레지스터, 범용 레지스터들, 상태 코드 정보가 포함된다.
이 상태 정보들과 프로그램 카운터는 나중에 프로세스가 다시 스케줄 될 때 기존의 작업을 올바르게 수행하기 위해서 인터럽트 발생 시 저장되어야 한다. - CPU-스케줄링 정보
프로세스 우선순위, 스케줄 큐에 대한 포인터와 다른 스케줄 매개변수를 포함한다. - 메모리 관리 정보
사용중인 메모리 시스템에 따라 기준 레지스터와 한계 레지스터의 값, 운영체제가 사용하는 메모리 시스템에 따라 페이지 테이블 또는 세그먼트 테이블 같은 정보를 포함한다. - 회계 정보
CPU 사용시간, 경과된 실시간, 시간 제한, 계정 번호, job 또는 프로세스 번호등을 포함한다. - 입출력 상태 정보
프로세스에 할당된 입출력 장치들과 열린 파일의 목록 등을 포함한다.
4. 스레드
지금까지의 프로세스는 단일 프로세스 + 단일 스레드 모델만 암시했다.
이러한 모델은 문자를 입력하면서 동시에 철자 검사기를 실행할 수 없다.
대부분의 현대 운영체제는 다중 스레드 모델을 허용한다.
따라서 프로세스가 한 번에 하나 이상의 일을 수행할 수 있도록 해준다.
프로세스 스케줄링
다중 프로그래밍의 목적은 CPU 이용을 최대화 하기 위해서 항상 어떤 프로세스가 실행되도록 하는데 있다. 따라서 프로세스의 스케줄링이 필요하다.
프로세스 스케줄러는 코어에서 실행 가능한 여러 프로세스 중에서 하나의 프로세스를 선택하는 역할을 한다.
다중 코어 시스템에서는 한 번에 여러 개의 프로세스를 실행할 수 있다. 그리고 현재 메모리에 있는 프로세스 수를 다중 프로그래밍 정도라고 한다.
일반적으로 대부분의 프로세스는 I/O 바운드 또는 CPU 바운드로 설명할 수 있다.
I/O 바운드 프로세스 : 계산에 소비하는 것보다 I/O에 더 많은 시간을 소비하는 프로세스
CPU 바운드 프로세스 : 계산에 더 많은 시간을 사용하여 I/O 요청을 자주 생성하지 않는 프로세스
1. 스케줄링 큐
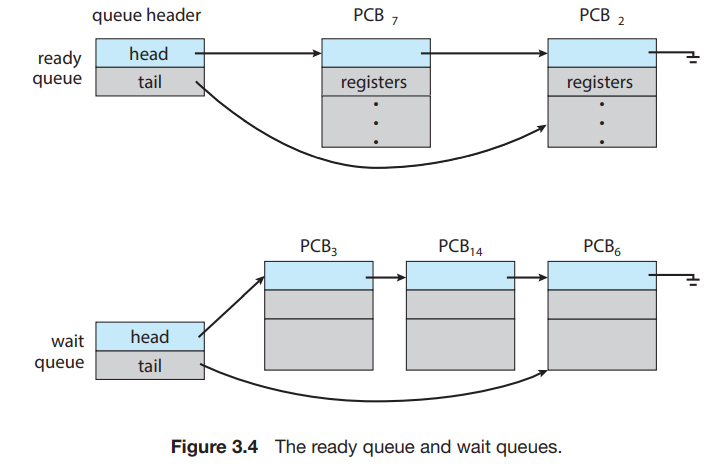
프로세스가 시스템에 들어가면 준비 큐에 들어가서 준비 상태가 되어 CPU 코어에서 실행되기를 기다린다. 이 큐는 일반적으로 연결 리스트로 저장된다.
준비 큐 헤더에는 리스트의 첫 번째 PCB에 대한 포인터가 저장되고 각 PCB에는 준비 큐의 다음 PCB를 가리키는 포인터 필드가 포함된다.
프로세스가 I/O 장치에 요청을 하면 많은 시간을 기다려야 할 수 있다. 따라서 I/O 완료와 같은 특정 이벤트가 발생하기를 기다리는 프로세스는 대기 큐에 삽입된다.
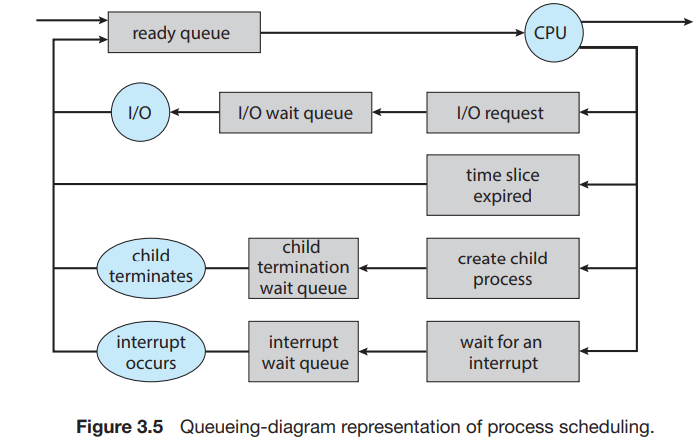
프로세스 스케줄링은 위와 같은 큐잉 다이어그램으로 표현될 수 있다.
하늘색 원은 큐에 서비스를 제공하는 자원을 나타내고 화살표는 시스템 프로세스의 흐름을 나타낸다.
새 프로세스는 처음에 준비 큐에 놓인다. 실행을 위해 선택되면 CPU를 통해 여러 이벤트 중 하나가 발생할 수 있다.
프로세스는 종료될 때까지 이러한 주기를 반복하고, 프로세스가 종료되면 모든 큐에서 제거되고 PCB 및 자원이 반환된다.
2. CPU 스케줄링
CPU 스케줄러의 역할은 준비 큐에 있는 프로세스 중에서 선택된 하나의 프로세스에 CPU 코어를 할당하는 것이다.
보통 100 밀리초마다 한 번씩 실행된다고 한다.
일부운영체제는 스와핑(Swapping)이라고 불리는 중간 형태의 스케줄링 기법을 사용한다.
스와핑은 디스크 공간을 프로세스가 유지되는 메모리 공간처럼 사용하는 기법을 의미한다.
프로세스를 메모리에서 디스크로 '스왑아웃'하고 현재 상태를 저장해놓는다. 이후 디스크에서 메모리를 '스왑인'하여 상태를 복원할 수 있기 때문에 이 기법을 '스와핑'이라고 한다.
일반적으로 메모리가 초과 사용되어 가용 공간을 확보해야 할 때만 필요하다.
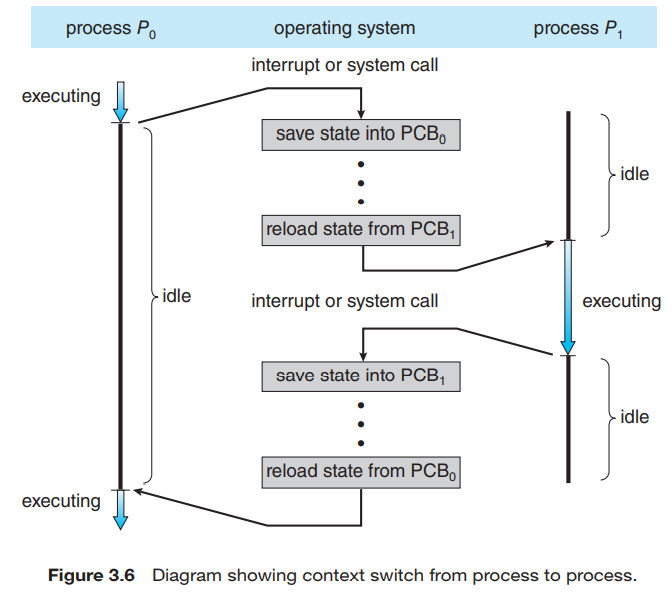
3. Context Switch(문맥 교환)
Context 라 하는것은 프로세스의 현재 실행 상태(문맥)을 의미한다. 인터럽트가 발생해서 CPU 코어를 빼앗긴 프로세스를 위해서 시스템은 인터럽트 처리가 끝난 후에 문맥을 복구할 수 있도록 해당 프로세스의 문맥을 저장해두어야 한다.
문맥은 PCB에 표현된다. 주로 CPU 레지스터의 값, 프로세스 상태, 메모리 관리 정보 등을 포함한다.
사용자 모드, 커널 모드에서 CPU의 현재 상태를 저장하는 작업을 수행하고, 나중에 연산을 재개하기 위해 상태 복구 작업을 수행한다.
따라서 Context Switch는 이전의 프로세스의 상태를 보관하고 새로운 프로세스의 보관된 상태를 복구하는 작업을 의미한다.
스위칭 동안에는 시스템은 아무런 작업을 하지 못한다. 그래서 Context switching 시간은 순수한 오버헤드가 된다.
스위칭에 걸리는 시간은 하드웨어의 지원에 따라 크게 달라진다.
프로세스에 대한 연산
1. 프로세스 생성
프로세스는 프로세스 식별자(pid)를 통해 구분된다. pid는 정수이고 고유한 값을 가진다.
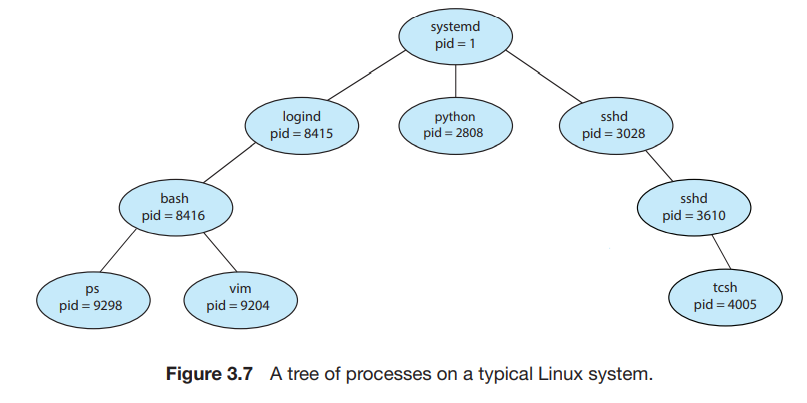
Linux 에서는 언제나 pid가 1인 systemd 프로세스가 첫 번째 사용자 프로세스이자 부모 프로세스가 된다.
systemd 프로세스로부터 logind, sshd 등등이 생겨나고, 다시 logind, sshd로부터 자식 프로세스들이 생긴다.
프로세스가 새로운 프로세스를 생성할 때, 두 프로세스를 실행시키는 방법
- 부모는 자식과 병행하게 실행을 계속한다.
- 부모는 일부 또는 모든 자식이 실행을 종료할 때까지 기다린다.
새로운 프로세스들의 주소 공간 측면에서 볼 때의 특징
- 자식 프로세스는 부모 프로세스의 복사본이다.
(자식 프로세스는 부모와 똑같은 프로그램과 데이터를 가진다) - 자식 프로세스가 자신에게 적재될 새로운 프로그램을 가지고 있다.
fork() 시스템 콜을 통해 자식 프로세스를 생성하는 과정
SystemSoftware - Creating Processes #1
OS에서 process를 만드는 방식에 대해서 알아보자 process는 fork()라는 syscall을 통해서 child process를 생성한다. fork를 호출한 process가 parent process가 되고, 새로 생긴 process가 child가 process이다...
hyeo-noo.tistory.com
프로그램 코드와 코드의 실행 순서

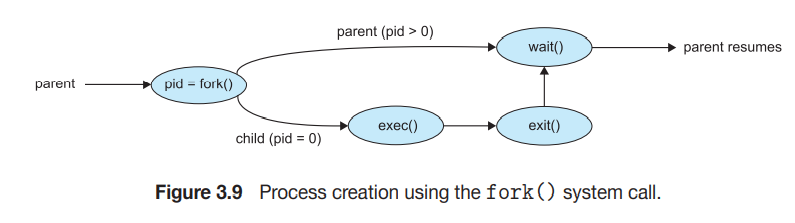
2. 프로세스 종료
프로세스를 종료하는 시스템 콜은 종료될 프로세스의 부모만이 호출할 수 있다.
그렇지 않으면, 사용자 또는 오작동하는 프로세스가 다른 사용자의 프로세스를 임의로 중단(kill)시킬 수 있을 것이다.
// 부모는 특정 자식 프로세스를 종료시키기 위해서 자식의 pid를 알아야 한다.
프로세스를 종료하는 이유
- 자식이 자신에게 할당된 자원을 초과하여 사용할 때
이때는 부모가 자식들의 상태를 검사할 수 있는 방법이 주어져야 한다. - 자식에게 할당된 태스크가 더 이상 필요 없을 때
- 부모가 exit를 하는데, 운영체제는 부모가 exit 한 후에 자식이 실행을 계속하는 것을 허용하지 않는 경우
프로세스 종료를 위한 wait() 시스템 콜과 zombie 및 orphan 프로세스에 대한 처리를 해주는 init() 프로세스
SystemSoftware - Creating Processes #2
SystemSoftware - Creating Processes #1 OS에서 process를 만드는 방식에 대해서 알아보자 process는 fork()라는 syscall을 통해서 child process를 생성한다. fork를 호출한 process가 parent process가 되고,..
hyeo-noo.tistory.com
프로세스 간 통신
독립적인 프로세스는 서로 다른 프로세스간 데이터를 공유하지 않는다.
협력적인 프로세스는 다른 프로세스들과 데이터를 공유한다.
프로세스 협력을 허용하는 환경을 제공하는 이유
- 정보 공유
여러 응용 프로그램이 동일한 정보에 흥미를 느낄 수 있으므로, 그러한 정보를 병행적으로 접근할 수 있는 환경을 제공해야한다. - 계산 가속화
특정 태스크를 빨리 실행하고자 한다면, 태스크를 여러개의 서브태스크로 나누고 이를 병렬로 실행되게 해야한다.
이러한 가속화는 2개 이상의 코어를 가지고 있어야 한다. - 모듈성
시스템 기능을 별도의 프로세스들 또는 스레드들로 나누어, 모듈식 형태로 시스템을 구성할 수 있다.
프로세스 간 통신(InterProcess Communication, IPC) 기법
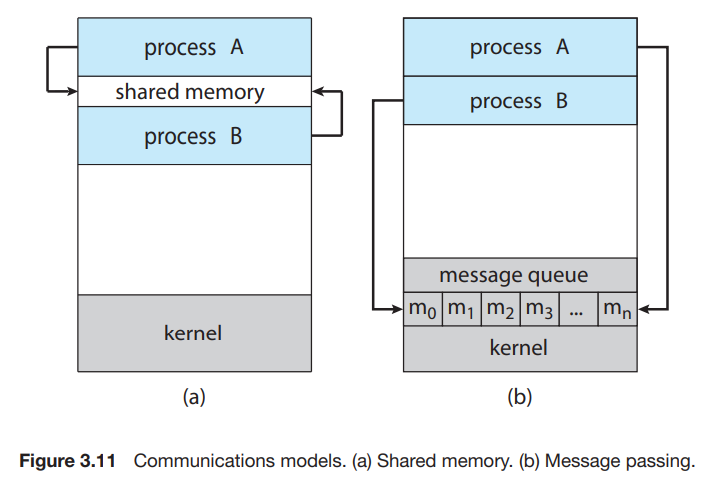
공유 메모리
- 속도 측면에서는 공유 메모리 모델이 더 빠르다.
- 공유 메모리 모델은 메모리 영역을 구축할 때만 시스템 콜이 필요하다.
메시지 전달
- 메시지 전달 모델은 충돌은 회피할 필요가 없기 때문에 적은 양의 데이터를 교환하는 데 유용하다.
- 메시지 전달은 분산 시스템에서 공유메모리보다 구현하기 쉽다.
- 메시지 전달은 시스템 콜은 사용하여 구현되므로 커널 간섭 등의 부가적인 시간 소비 작업이 필요하다.
공유 메모리 시스템
기본 개념
A 프로세스는 자신의 공유 메모리 세그먼트가 존재한다. A 프로세스와 통신하기 위한 B 프로세스는 자신(B)의 주소공간에 A의 공유 메모리 세그먼트를 추가한다. (주소 공간 참조)
일반적으로 운영체제에서는 프로세스간의 메모리 접근을 금지하지만, 이 시스템을 원하는 프로세스는 이 제약 조건을 무시하는 것에 동의해야 한다.
따라서 데이터의 형식과 위치는 이들 프로세스에 의해 결정되며, 운영체제의 소관이 아니게 된다.
생산자-소비자 문제
생산자 프로세스는 정보를 생산하고 소비자 프로세스는 정보를 소비한다.
일반적으로 서버를 생산자로 클라이언트를 소비자로 볼 수 있다.
일반적으로 생산하는 속도와 소비하는 속도에 차이가 존재한다. 실제로 생산되는 속도가 소비하는 속도보다 빠른 경우가 많아서 생산된 데이터는 바로 소비되지 못한다. 이를 보완하기 위해 생산된 데이터를 보관하는 버퍼라는 공간이 존재한다. 생산자가 데이터를 생산하면 버퍼에 보관을 하게 되고 소비자는 버퍼에서 데이터를 빼내어 사용한다. 하지만 현실 시스템에는 버퍼의 크기가 유한하다. 크기가 정해져 있는 버퍼이기 때문에 Bounded Buffer(유한 버퍼)라고 불린다. 생산자는 버퍼가 가득 차면 더 이상 넣을 수가 없다. 반대로 소비자는 버퍼가 비면 뺄 수가 없다.

공유 버퍼는 두 개의 논리 포인터 in과 out을 갖는 원형 배열로 구현된다.
in은 버퍼 내에서 다음으로 비어 있는 위치를 가리킨다.
out은 버퍼 내에서 첫 번째로 채워져 있는 위치를 가리킨다.
in == out일 때 버퍼는 비어있다는 뜻이되고(비어있는데 첫 번째로 채워져 있다는게 모순이 되므로 버퍼가 비어있다고 해석하는 것 같다),
((in+1)% BUFFER_SIZE == out)이면 버퍼는 가득 차 있다는 뜻이다. (실제로는 아닐 수 있다)


위 코드를 통한 방법은 최대 BUFFER_SIZE - 1 까지만의 데이버를 버퍼에 수용할 수 있다.
buffer_size = 5이고, in = 4, out = 0인 경우를 생각해보자.
이때 버퍼의 5번째 공간(인덱스는 4)은 비어있지만 코드 상에서 (in + 1) % BUFFER_SIZE == 0 ((4 + 1) % 5 = 0) 이므로 버퍼의 마지막 5번째 공간을 사용하지 못한다.
버퍼의 모든 공간을 사용하기 위해서는 (in + 1) % BUFFER_SIZE 말고 in % BUFFER_SIZE 연산을 수행하면 될 듯하다.
메시지 전달 시스템
메시지 전달 방식은 동일한 주소 공간을 공유하지 않고도 프로세스들이 통신을 하고, 그들의 동작을 동기화할 수 있도록 허용하는 기법을 제공한다. 이 방법은 특히 프로세스들이 네트워크를 통해 연결된 다른컴퓨터들에 존재하는 경우에 유용하다.
메시지 시스템의 주요 연산
send(message), receive(message)
프로세스 P와 Q가 통신을 원하면 통신 연결을 설정해야 한다.
연결의 논리적인 구현 방법은 다음과 같다.
- 직접 또는 간접 통신
- 동기식 또는 비동기식 통신
- 자동 또는 명시적 버퍼링
직접 통신 방법
1. 대칭적 방법
send(P, message) - 프로세스 P에 메시지를 전송한다.
receive(Q, message) - 프로세스 Q로부터 메시지를 수신한다.
특징
- 통신을 원하는 프로세스 쌍 사이의 연결이 자동으로 구축된다.
프로세스들은 통신하기 위해 상대방의 신원만 알면 된다. - 연결은 정확히 두 프로세스 사이에만 연관된다.
- 통신하는 프로세스들의 각 쌍 사이에는 정확히 하나의 연결이 존재해야 한다.
대칭성
- 송신자와 수신자 프로세스가 모두 통신하려면 상대방의 이름을 제시해야 한다.
2. 비대칭적 방법
send(P, message) - 메시지를 프로세스 P에 전송한다.
receive(id, message) - 임의의 프로세스로부터 메시지를 수신한다. 변수 id는 통신을 발생시킨 프로세스의 이름으로 설정된다.
직접 통신방법의 단점
프로세스를 지정하는 방식 때문에 모듈성을 제한한다. 프로세스의 이름을 바꾸면 모든 다른 프로세스 지정 부분을 검사해야 한다. (하드 코딩 기법)
간접 통신 방법
간접 통신에서 메시지들은 메일박스 또는 포트로 송신, 수신 된다.
메일박스는 추상적으로 프로세스들에 의해 메시지들이 넣어지고, 메시지들이 제거될 수 있는 객체라고 볼 수 있다.
send(A, message) - 메시지를 메일박스 A로 전송한다.
receive(A, message) - 메시지를 메일박스 A로부터 수신한다.
특징
- 항 쌍의 프로세스들 사이의 연결은 이들이 공유 메일박스를 가질 때만 구축된다
- 연결은 두 개 이상의 프로세스들과 연관될 수 있다.
- 통신하고 있는 각 프로세스 사이에는 다수의 서로 다른 연결이 존재할 수 있고, 각 연결은 하나의 메일박스에 대응된다.
메일박스에 대한 추가 설명
메일박스는 누가 만드는가?
메일박스는 하나의 프로세스 또는 운영체제에 의해 소유될 수 있다.
메일박스가 한 프로세스에 의해 소유된다면(프로세스 주소공간의 일부), 메일박스에 메시지를 넣는 프로세스(소유자)와 메일박스에서 메시지를 가져가는 프로세스(사용자)를 구분할 수 있다. 만약 메일박스를 소유하고있는 프로세스가 종료된다면 메일박스의 사용자들에게 이를 알려야 할 필요가 있다.
운영체제가 메일박스를 소유한다면 1. 새로운 메일박스를 생성, 2. 메일박스를 통해 메시지를 송신하고 수신, 3. 메일박스 삭제 시스템을 모두 구현해야 할 것이다. 새로운 메일박스를 생성하는 프로세스는 초기에 메일박스의 소유자가 될 것이고, 나중에는 적절한 시스템 콜을 통해서 권한이 전달될 수 있다.
동기화
프로세스간 통신은 동기식, 비동기식 방법이 있다.
- 동기식 보내기(봉쇄형 보내기)
송신하는 프로세스는 메시지가 수신 프로세스 또는 메일박스에 의해 수신될 때까지 봉쇄된다. - 비동기식 보내기(비봉쇄형 보내기)
송신하는 프로세스가 메시지를 보내고 작업을 재시작한다. - 동기식 받기(봉쇄형 받기)
메시지가 이용 가능할 때까지 수신 프로세스가 봉쇄된다. - 비동기식 받기(비봉쇄형 받기)
송신하는 프로세스가 유효한 메시지 또는 null을 받는다.


버퍼링
메시지 전달 시스템에는 메시지를 전달하는 일종의 큐가 존재한다.
큐를 구현하는 3가지 방법
- 무용량
큐의 길이가 0이라서 송신자는 수신자가 메시지를 수신할 때까지 기다려야 한다. - 유한 용량
큐의 길이에 제한이 있다. 큐가 가득 차있다면, 송신자는 큐 안에 공간이 날 때까지 봉쇄된다. - 무한 용량
송신자는 메시지를 계속 큐로 보낼 수 있다.
IPC 시스템
[OS] IPC 시스템의 사례(Examples of IPC Systems)
IPC 시스템의 사례(Examples of IPC Systems) [OS] 프로세스 간 통신(Interprocess Communication, IPC) 프로세스 간 통신(IPC) 운영체제 내에서 실행되는 병행 프로세스들은 독립적이거나 또는 협력적인 프로세..
dkswnkk.tistory.com
클라이언트-서버 환경 통신
소켓이란?
소켓은 통신의 endpoint를 뜻한다.
두 프로세스가 네트워크상에서 통신을 하려면 각 프로세스마다 하나씩, 총 두 개의 소켓이 필요하다.
각 소켓은 IP 주소와 포트 번호 두 가지를 합쳐서 구별한다.
일반적으로 소켓은 클라이언트-서버 구조를 사용한다.
서버는 지정된 포트에 클라이언트 요청 메시지가 도착하기를 기다린다.
요청이 수신되면 서버는 클라이언트 소켓으로부터 연결 요청을 수락함으로써 연결이 완성된다.
Telnet, FTP, HTTP 등의 특정 서비스를 구현하는 서버는 well-known 포트로부터 메시지를 기다린다.
예를 들어 SSH는 22번 포트, FTP 서버는 21번 포트, HTTP는 80번 포트를 사용한다.
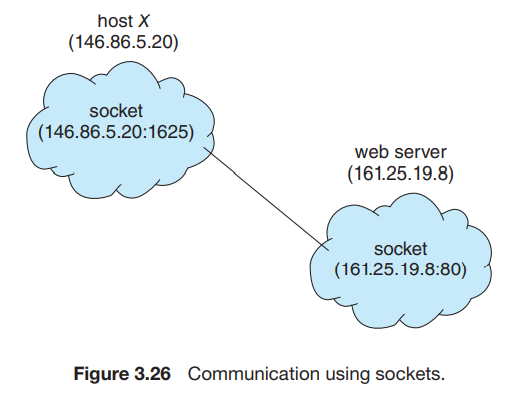
연결 기반 TCP 통신 요약 (3way handshake)
- hostX가 web server에게 연결 요청을 보낸다. (SYN 패킷)
- web server는 hostX에게 포트번호 1625를 부여하고, 패킷을 받았음을 알리는 ACK와 연결을 허락한다는 SYN flag 패킷을 보낸다.
- hostX는 web server의 메시지를 받았음을 확인하는 ACK 패킷을 다시 web server로 보내고 두 프로세스 사이의 소켓이 개통된다.
추가적인 정보들
[운영체제] 클라이언트 서버 환경에서 통신(Communication in Client-Server Systems)
이전에 협력적 프로세스들은 데이터를 교환할 수있는, 즉 서로 데이터를 보내거나 받을 수있는 '프로...
blog.naver.com
연습 문제

3.1 위 그림에서 표시된 프로그램을 사용하여 LINE A에서 출력되는 내용을 설명하라.
PARENT: value = 5
부모와 자식간의 스택, 힙 영역은 공유되지 않는다.

3.2 최초의 부모 프로세스를 포함하여 위 그림에 표시된 프로그램에 의해 몇 개의 프로세스가 생성되는가?
8개
3.3 Apple 모바일 iOS 운영체제의 원래 버전은 병행 처리 기법을 제공하지 않았다. 병행 처리로 인해 운영체제에 추가되는 세 가지 주요 문제에 대해 논의하라.
3.4 일부 컴퓨터 시스템은 다수의 레지스터 집합을 제공한다. 새 문맥이 레지스터 집합 중 하나에 이미 적재된 경우 문맥 교환 시 어떤 일이 발생하는지 설명하라.
CPU의 현재 context 포인터를 새로운 context가 가진 포인터로 변경한다.
이 작업은 매우 빠르게 진행된다.
새 문맥이 레지스터 집합이 아닌 메모리에 있고 모든 레지스터 집합이 사용중이라면 어떤 일이 발생하는가?
임의의 한 레지스터에 있는 context가 메모리로 옮겨진다. 그리고 새 context가 메모리에서 비워진 레지스터로 옮겨진다.
이 과정은 메모리를 참조하기 때문에 약간의 시간이 더 걸리게 된다.
3.5 프로세스가 fork() 연산을 사용하여 새로운 프로세스를 생성할 때 어떤 상태가 부모 프로세스와 자식 프로세스 간에 공유되는가?
A. 스택
B. 힙
C. 공유 메모리 세그먼트
C. 공유 메모리 세그먼트가 공유된다. fork()를 통해서 자식 프로세스를 만들면 부모 프로세스로부터 복사된 stack과 heap 영역은 자식 프로세스만의 것이 된다. 따라서 부모와 자식간의 stack, heap 상태는 더이상 공유되지 않는다.
'CS > OS' 카테고리의 다른 글
| [운영체제] Ch5. CPU 스케줄링 (0) | 2022.02.18 |
|---|---|
| [운영체제] Ch4. 스레드와 병행성 (0) | 2022.02.11 |
| [운영체제] Ch2. 운영체제 구조 (0) | 2022.02.06 |
| [운영체제] Ch1. 서론 (0) | 2022.02.01 |
| [OS] Virtual Memory #1 (0) | 2021.07.21 |