![[kubernetes] #10 쿠버네티스 영속성 데이터와 볼륨](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FW2gOe%2FbtrvY4RM0tp%2FBDSasppM17gf86EWQLpZ5k%2Fimg.png)
서론

Persistent Volume, Persistent Volume Claim, Storage Class를 사용해서 쿠버네티스 데이터를 영구적으로 유지하는 방법을 알아보자.
볼륨의 필요성
애플리케이션이 mysql 파드를 사용한다고 가정하자.
애플리케이션을 사용할 수록 데이터는 업데이트되고, 생성될 것이다.
하지만 mysql 파드가 재시작 되면 내부의 데이터는 모두 초기화 될 것이다.
쿠버네티스는 기본적으로 데이터의 영속성을 제공하지 않기 때문에 파드의 라이프사이클에 관계없이 데이터를 보존하고 싶다면, 별도의 저장소가 필요하다.
그리고 저장소는 어디에 생성될 지 알 수 없기 때문에 모든 노드에 대해서 접근이 가능해야 한다.
그리고 저장소는 쿠버네티스 클러스터가 파괴되어도 영향을 받아서는 안된다.
위 조건들을 만족해야만 믿을 수 있는 저장소의 조건을 충족시켰다고 할 수 있다.
Persistent Volume
PersistentVolume은 RAM, CPU 처럼 클러스터 자원의 일부이다.
따라서 다른 쿠버네티스 컴포넌트처럼 yaml 파일 형식을 통해서 생성될 수 있다.
kind는 PersistentVolume 으로 설정되고, spec에는 저장소의 용량 등을 설정할 수 있다.
PersistentVolume의 개념이 추상적으로 느껴지지만, 물리 저장소의 일정 부분을 사용한다는 점을 이해해야 한다.
그래서 쿠버네티스는 물리 저장소를 참조하는 PersistentVolume을 사용하기 위한 인터페이스를 제공할 뿐이다.
우리는 저장소가 연결될 서비스나 애플리케이션을 결정하고, 스스로 관리하면 된다.
위 그림처럼 현재 클러스터 노드의 local Disk 공간을 볼륨으로 사용해서 애플리케이션과 연결할 수도 있고, 클라우드 nft서버의 공간을 볼륨으로 참조해서 연결할 수도 있다.
PersistentVolume YAML
물리 저장소를 사용하기 위한 세부 설정은 spec 부분에서 결정한다.
저장소 타입에 따라서 spec 부분에 설정될 인자들이 달라진다.
공식적으로 20개 정도의 저장소 백엔드를 지원한다.
볼륨
컨테이너 내의 디스크에 있는 파일은 임시적이며, 컨테이너에서 실행될 때 애플리케이션에 적지 않은 몇 가지 문제가 발생한다. 한 가지 문제는 컨테이너가 크래시될 때 파일이 손실된다는 것
kubernetes.io
local, AWS EBS, emptyDir, hostpath .. 등등 정말 많은 볼륨 타입이 있고, 이들이 필요한 spec이 다르므로 위 사이트를 참고해서 yaml 파일을 설정하면 된다.
PersistentVolume 의 특징
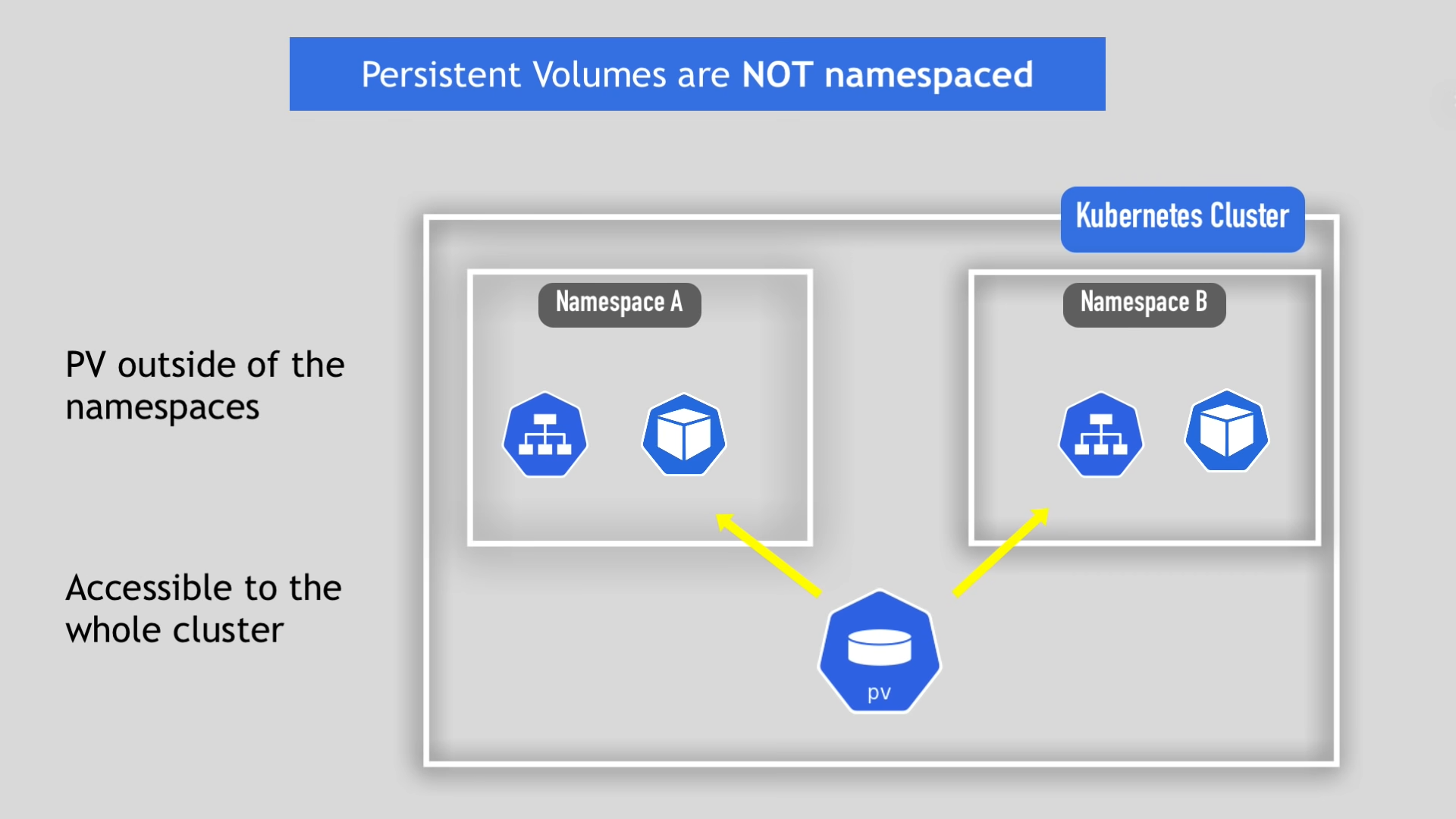
- PersistentVolume 은 특정 namespace에 속할 수 없다.
왜냐하면 위에서도 언급했듯이 모든 노드에서 접근할 수 있어야 됨과 동시에, 쿠버네티스 클러스터 내부의 모든 오브젝트가 참조할 수 있어야 하기 때문이다.
- PersistentVolume은 CPU, RAM 같은 쿠버네티스 자원이다.
따라서 파드가 자원을 사용하기 위해서 미리 가용한 자원이 있어야 하는 것 처럼, 볼륨도 미리 생성되어 있어야 한다.
Local vs. Remote Volume Types
볼륨을 크게 두 부분으로 나눈다면 Local과 Remote 볼륨으로 나눌 수 있다.
로컬 볼륨은 쿠버네티스 저장소의 2가지 원칙을 위반한다.
- 하나의 노드에 종속되어선 안된다.
- 클러스터가 파괴되어도 유지되어야 한다.
로컬 볼륨은 하나의 노드(자신)에 종속될 수 밖에 없고,
해당 노드의 클러스터가 파괴되면 볼륨도 같이 사라지게 된다.
따라서 원격 저장소를 사용하는 것을 추천한다.
K8s관리자와 사용자
개발팀에는 K8s 관리자와 K8s 사용자가 존재할 수 있다. 물론 둘 다 DevOps 엔지니어 일 것이다.
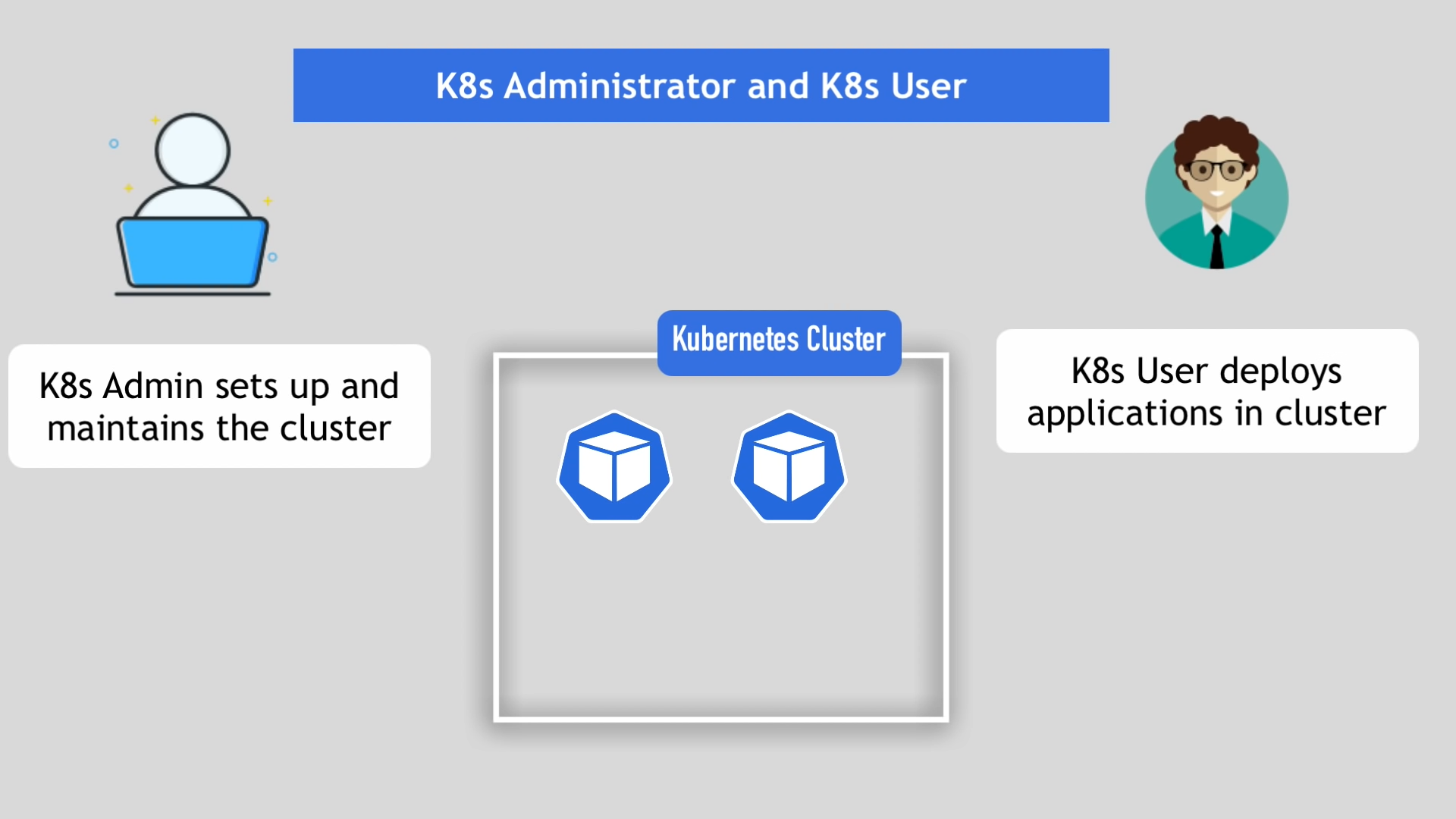
PersistentVolume 의 특징에서 볼륨이 파드에서 사용되기 위해서는 파드보다 먼저 생성되어 있어야 한다고 했다.
따라서 K8s 관리자는 쿠버네티스 클러스터의 컴포넌트를 생성, 관리하는 역할을 하며, 볼륨의 생성, 관리도 책임질 수 있다.
그리고 K8s 사용자는 개발된 애플리케이션을 CI 파이프라인을 통해서 배포하는 역할을 할 것이다.
PersistentVolumeClaim
K8s 관리자는 실질적인 저장소를 설정해야한다.
nfs 서버 저장소 또는 Cloud 저장소를 클러스터에서 사용할 수 있도록 설정할 것이다.
그리고 PersistentVolume을 생성하고 저장소 백엔드를 nfs 또는 Cloud로 설정할 수 있을 것이다.
이렇게 설정을 마치면 사용자는 새로운 저장소를 사용할 수 있다는 것을 알게 될 것이다.
생성되어있는 볼륨을 연결해 사용하기 위해서는 사용을 원하는 볼륨의 정보가 적힌 yaml 파일이 필요하다.
이를 위해서 PersistentVolumeClaim(PV claim : PVC)이 존재한다.
PersistentVolumeClaim은 일종의 컴포넌트로서 애플리케이션이 사용할 볼륨을 연결해주는 징검다리 역할을 함과 동시에, 볼륨의 추상화를 도와준다.
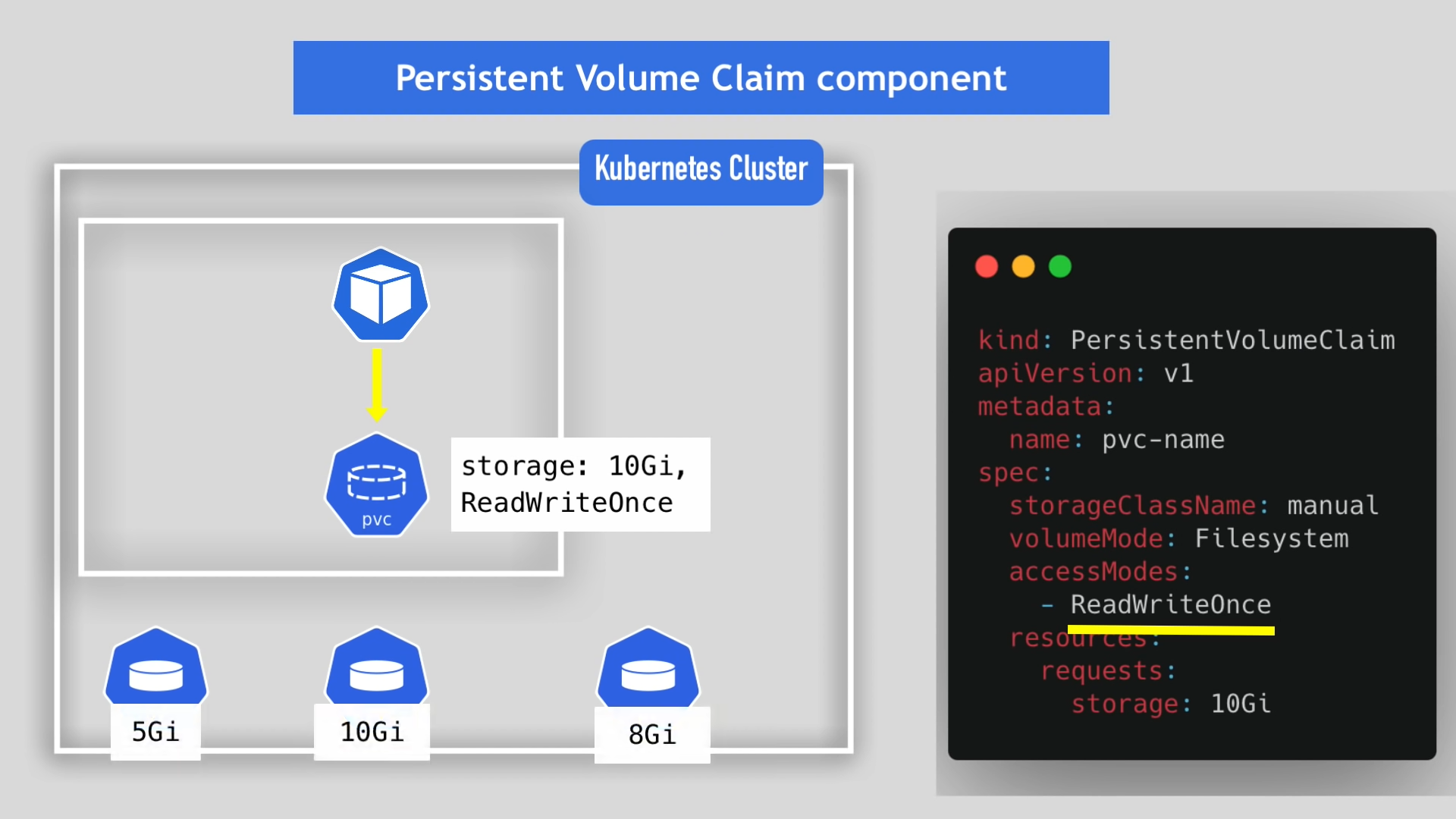
PersistentVolumeClaim.yaml 파일에 애플리케이션이 사용할 볼륨의 특성을 명시적으로 적어주면, 특성과 일치하는 볼륨을 찾아서 연결시켜 준다.
위 그림에서는 PVC에 10Gi 인 볼륨을 연결하라고 명시해 놓았다. 따라서 PVC컴포넌트는 이미 만들어져 있는 볼륨 중 용량이 10Gi 인 볼륨과 파드를 연결해 줄 것이다.
PersistentVolumeClaim이 파드와 PersistentVolume을 연결해 준다는 사실을 알게 되었다.
따라서 파드에는 PersistentVolumeClaim에 대한 정보가 추가적으로 입력되어야 할 것이다.
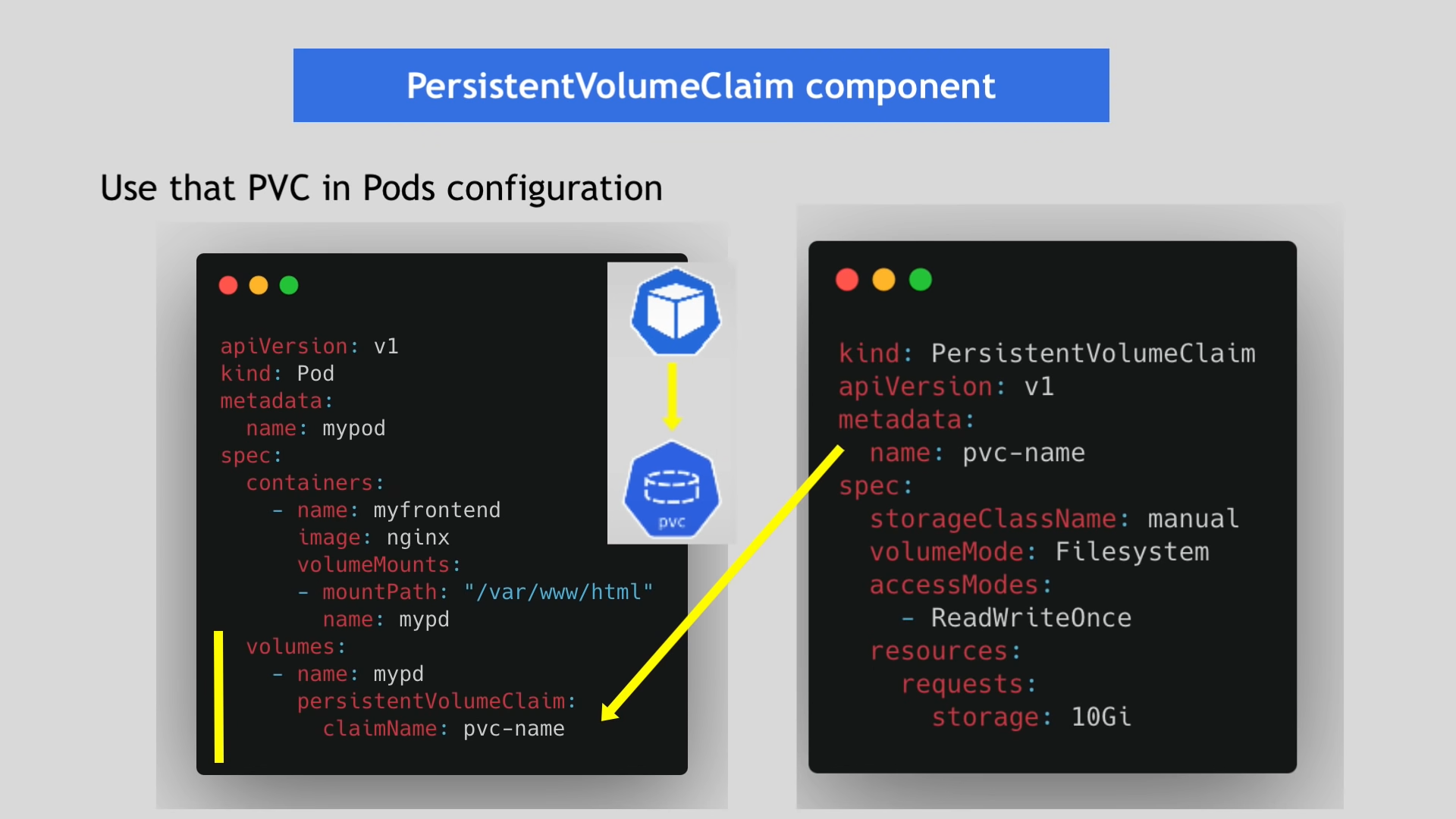
파드의 claimName과 PersistentVolumeClaim의 metadata.name을 일치시켜서 연결할 수 있다.
주의할 점은 PVC와 이를 사용하는 파드는 같은 namespace에 속해야 한다는 점이다.
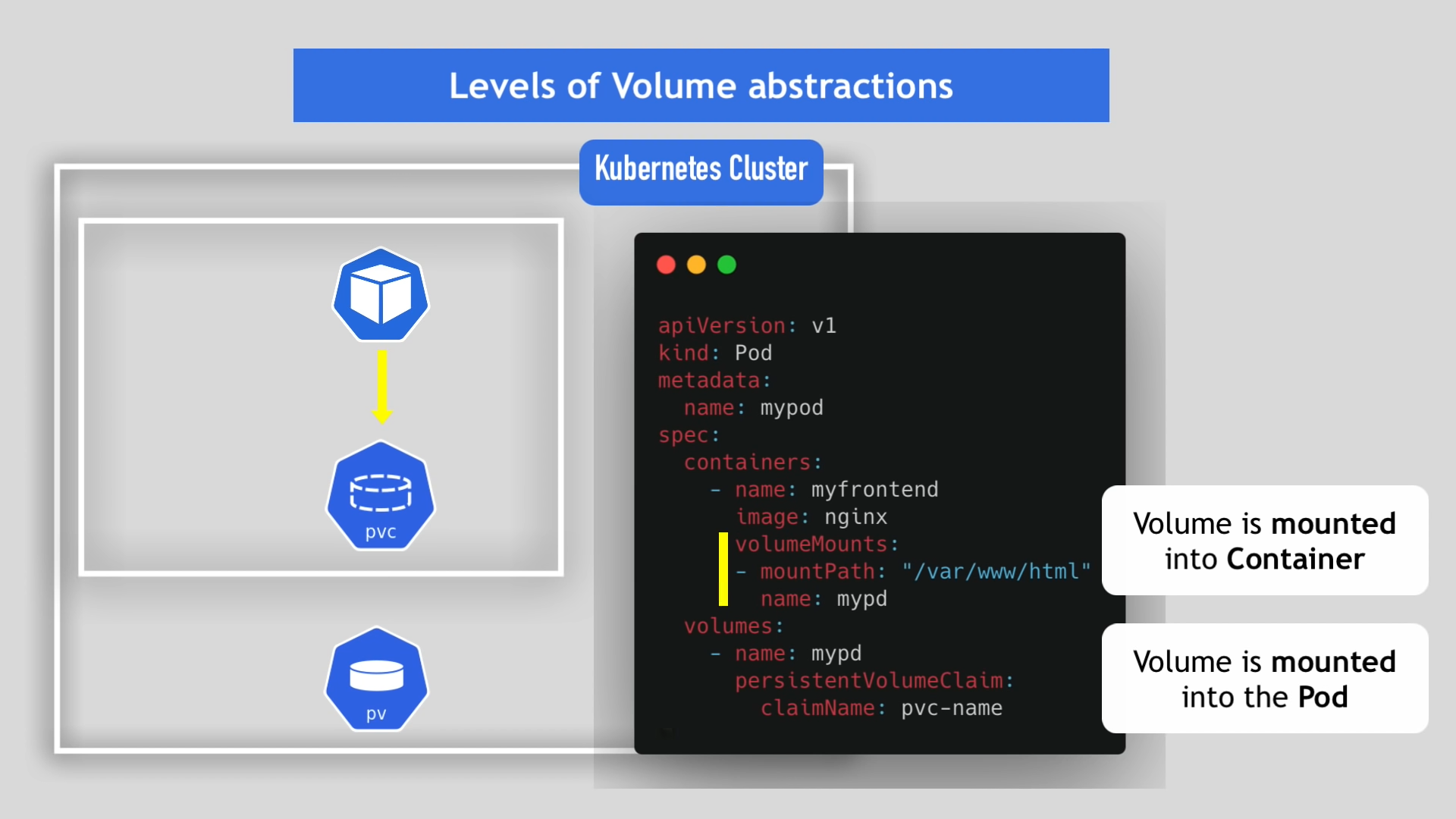
볼륨은 파드에 마운트됨과 동시에 파드의 컨테이너의 명시된 path에 마운트된다.
- 파드는 PVC를 통해서 볼륨과의 연결을 명시한다.
- PVC는 알맞은 볼륨을 찾아준다.
- 볼륨은 자신을 요청한 파드의 컨테이너 내부의 특정 path에 마운트 된다.
마운트 과정 덕분에 파드는 자신의 컨테이너에 있는 데이터를 수정하면 외부의 저장소에 있는 데이터를 수정하는 것과 같은 효과를 낼 수 있게 된다.
그리고 파드가 파괴되어 새로운 컨테이너로 교체된다해도, 기존의 저장소가 그대로 마운트되므로 데이터의 손실 없이 작업이 가능하다.
왜 볼륨은 많은 단계에 걸쳐서 추상화를 적용할까?
우선 관리자와 사용자의 역할을 살펴보자
- K8s 관리자는 저장소(PV)를 공급해준다.
- K8s 사용자는 PV에 대한 Claim을 생성한다.
역할이 명확히 나뉘어 있다.
덕분에 K8s 사용자는 실질적인 저장소가 cloud에 있는지, 로컬에 있는지 등을 전혀 알 필요없다.
저장소가 잘 동작한다고 가정하고 모든 작업을 할 수 있다.
단순히 50Gi의 용량이 필요하거나 10Gi의 용량이 필요하다, 이정도의 요구사항만 있으면 충분하다.
볼륨의 추상화 덕분에 개발자는 데이터의 영속성에 관해서 전혀 신경을 쓰지 않아도 되므로 편하게 개발할 수 있다는 큰 장점을 얻게된다.
ConfigMap 과 Secret
볼륨 타입의 일종인 ConfigMap과 Secret에 대해 짚고 넘어가자
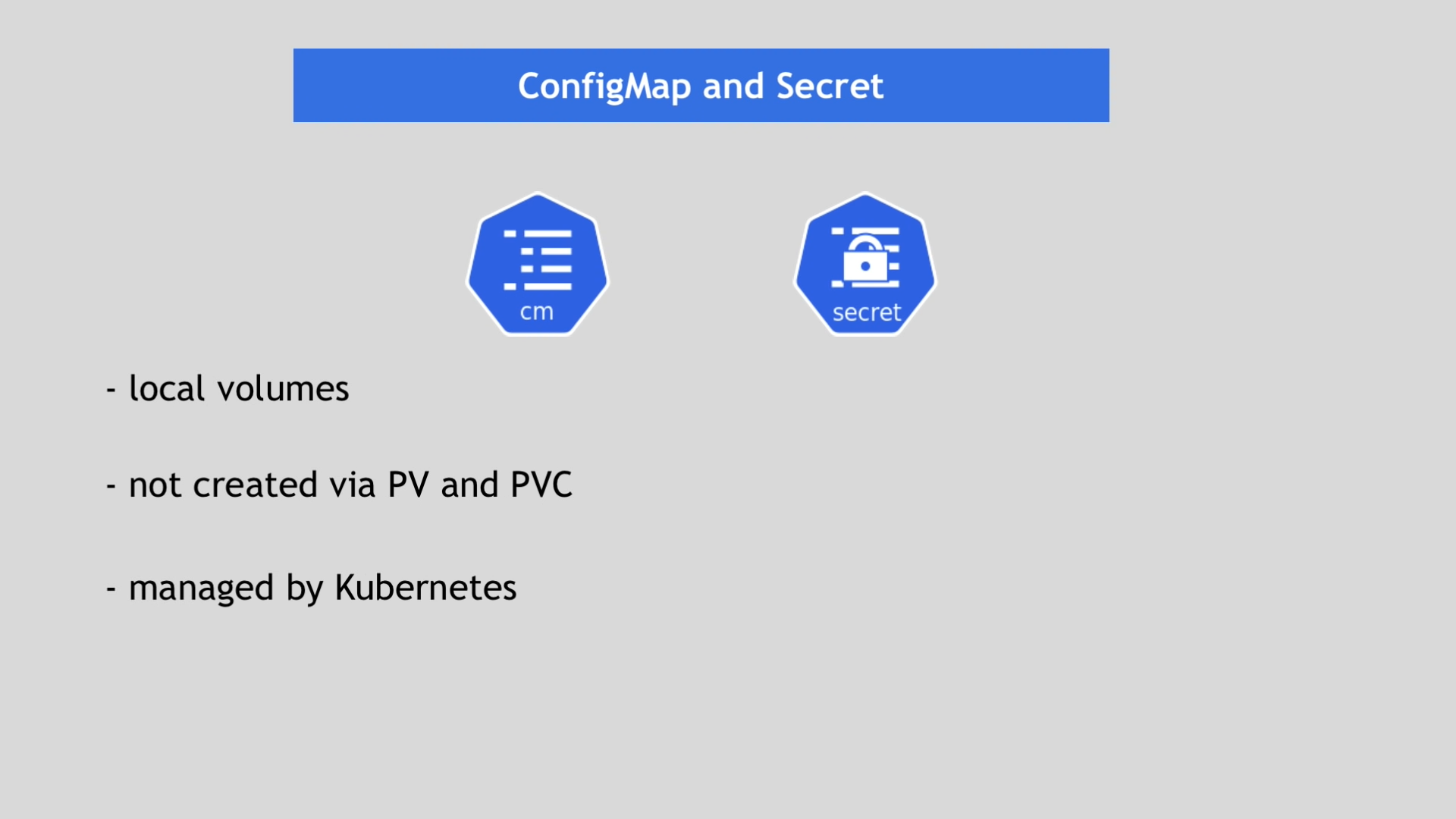
- Local 볼륨이다.
- PV와 PVC를 통해 생성되지 않는다.
- 쿠버네티스를 통해 관리된다.
예를 들어 메시지 브로커나 모니터링 앱을 사용하기 위해서 애플리케이션 자체에서 설정해야 할 정보들은 쿠버네티스 클러스터 내부의 ConfigMap이나 Secret을 통해서 참조된다.
ConfigMap과 Secret에 있는 정보들은 PV와 파드가 마운팅을 통해 데이터를 공유하는, 이 방법을 동일하게 사용해서 참조된다. 즉 ConfigMap과 Secret 파일을 파드/컨테이너와 마운트해서 공유한다는 뜻이다.
정리
- 볼륨은 데이터를 저장하기 위한 디렉토리이다.
- 볼륨은 파드의 컨테이너 내부에서 접근할 수 있다.
- 볼륨은 반드시 세부적인 타입이 정해져야 한다. (local, aws ebs, nfs ...)
Storage Class
Storage Class(SC)는 PersistentVolumeClaim이 요청할 때, 동적으로 생성되는 PersistentVolume 이다.
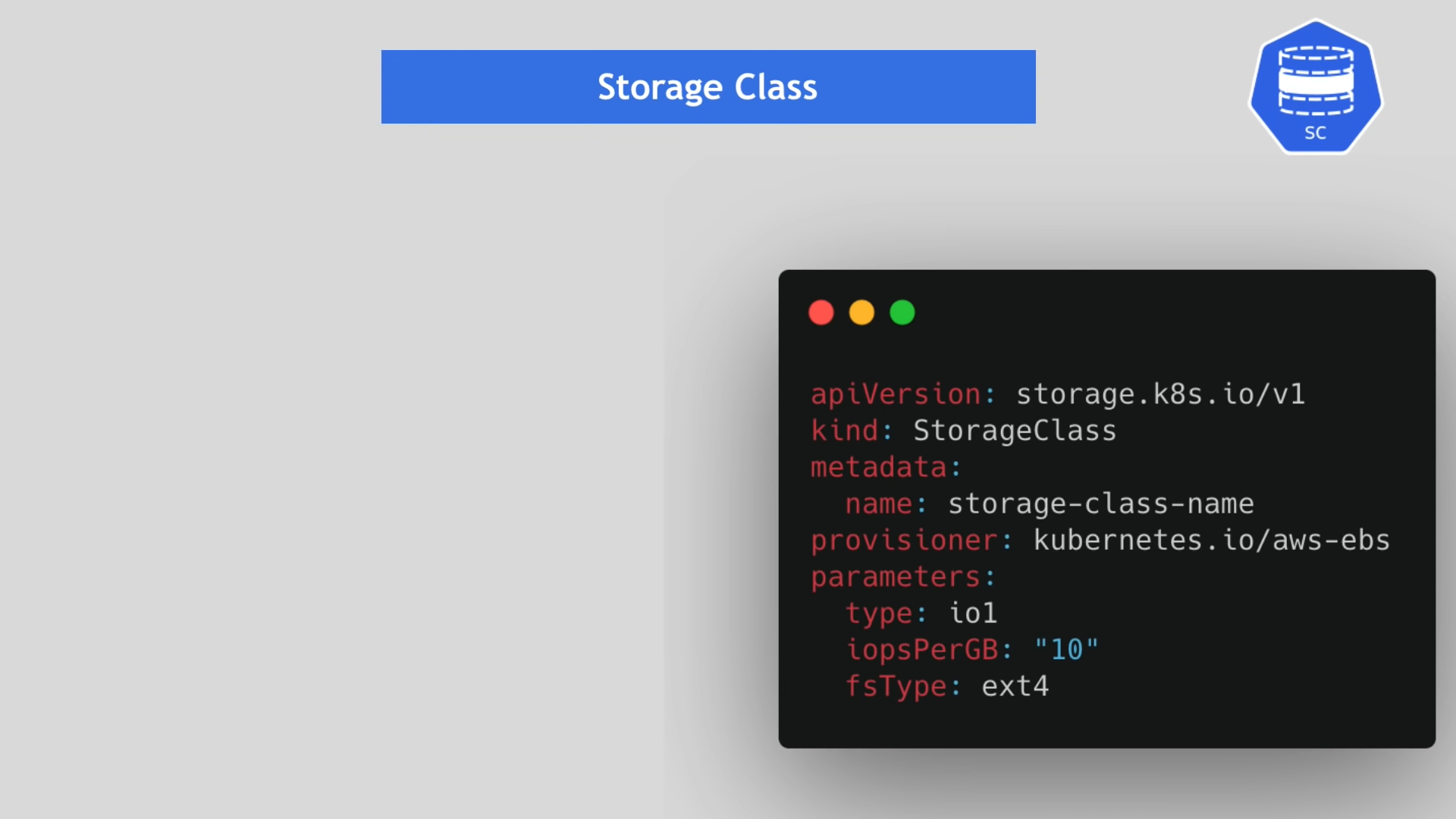
kind: StorageClass
StorageBackend는 provisioner 속성을 통해서 정의할 수 있다. (모든 저장소 백엔드는 자신만의 공급자가 존재한다.)
- 내부 공급자는 "kubernetes.io"
- 외부 공급자는 적절하게 입력하기
파라미터 속성은 생성될 볼륨의 정보를 입력해 준다.
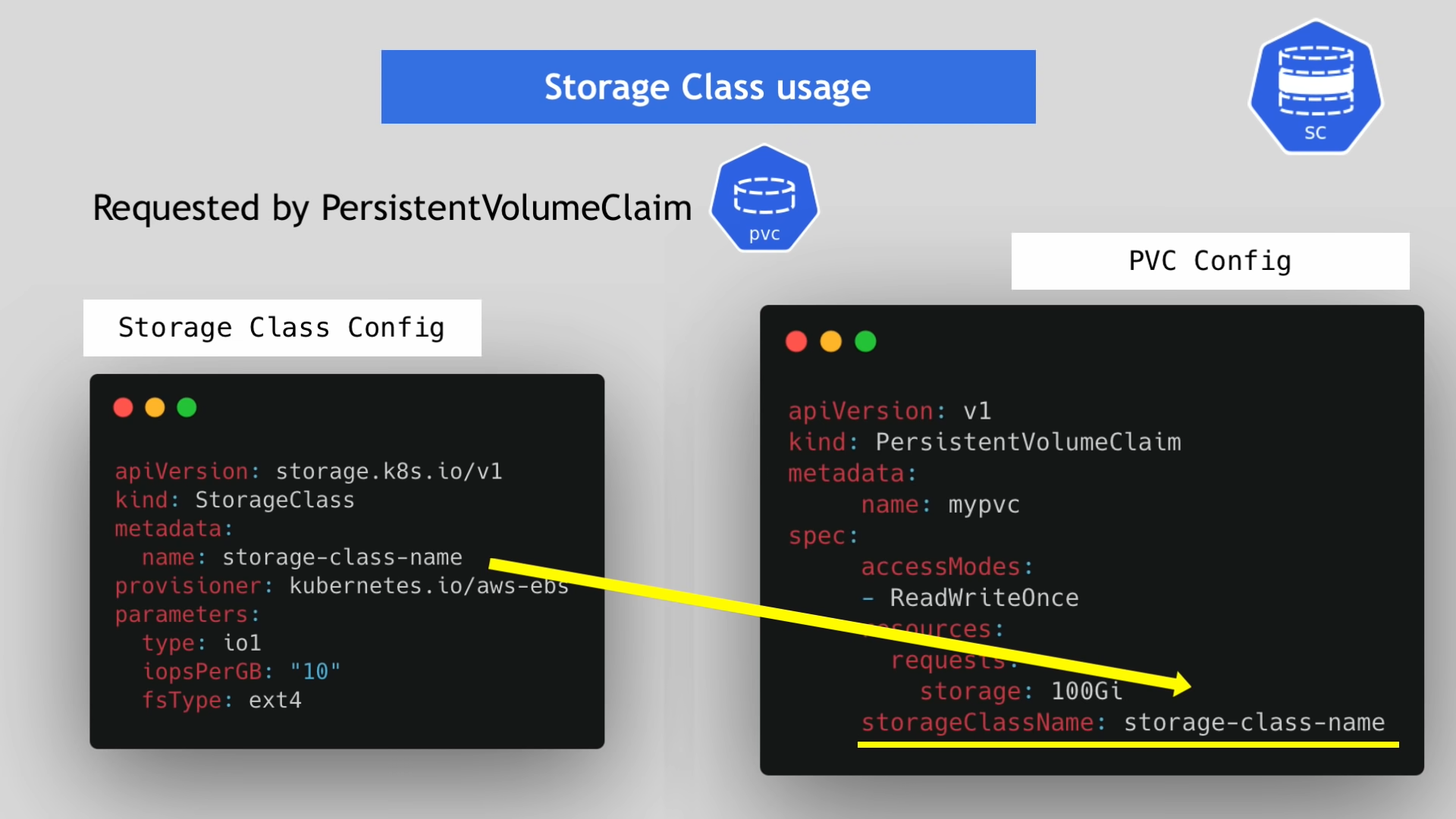
PVC는 SC와 연결하기 위해서 SC의 metadata.name을 참조해야 한다.
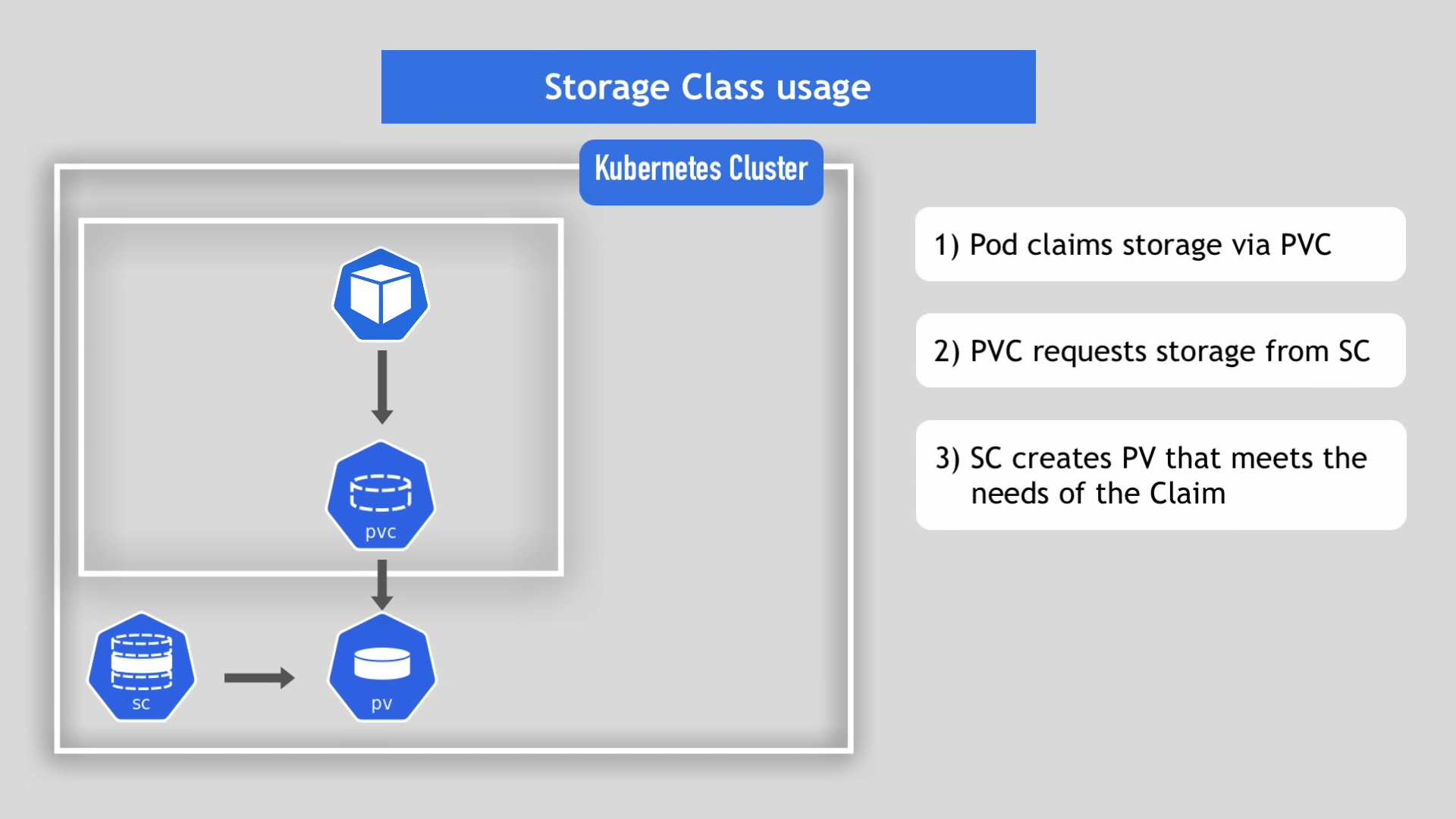
- 파드는 PVC를 통해서 저장소를 요청한다.
- PVC는 SC를 통해서 저장소의 생성을 요청한다.
- SC는 PVC가 요청한 저장소의 스펙에 맞게 PV를 생성해준다.
- 파드와 PV가 연결된다.
출처 : https://www.youtube.com/watch?v=X48VuDVv0do
번역 : 나
Chapter : Persisting Data in K8s with Volumes
'DevOps > Kubernetes' 카테고리의 다른 글
| [kubernetes] Helm으로 nginx ingress controller 설치하기 (1) | 2022.04.04 |
|---|---|
| [Kubernetes] No Ingressclass resource with name nginx found 문제 해결하기 (Helm stable repo) (0) | 2022.03.31 |
| [kubernetes] #9 쿠버네티스 Ingress 란? (0) | 2022.03.09 |
| [kubernetes] VirtualBox의 Minikube Service 노출시키기 (0) | 2022.03.09 |
| [kubernetes] #8 네임스페이스를 통해 컴포넌트 구성하기 (0) | 2022.03.06 |