![[운영체제] Ch10. 가상 메모리](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbwXG3l%2Fbtrv6dPi0Gn%2FvOUsDUilPwzVZR6IGZadK1%2Fimg.jpg)

공룡책(운영체제)을 읽고 정리한 글입니다.
가상 메모리 개념은 어떻게 탄생한 것일까?
현재 실행되고 있는 코드는 반드시 물리 메모리에 존재해야 한다는 사실은 너무나 당연하고 기본적인 조건으로 보인다.
이 요구조건을 가장 쉽게 만족시키는 방법은 전체 프로세스를 메모리에 올리는 것이다.
하지만 이러한 방법은 프로그램의 크기를 물리 메모리의 크기로 제한한다는 점 때문에 마냥 좋지많은 않다.
실제로 많은 경우에 프로그램 전체가 한꺼번에 메모리에 늘 올라와있어야 할 필요는 없다는 사실을 알 수 있다.
- 프로그램에는 잘 발생하지 않는 오류 상황을 처리하는 코드가 종종 존재한다. 이러한 오류들은 실질적으로 거의 발생하지 않으므로, 이 코드들은 거의 실행되지 않는다.
- 배열, 리스트, 테이블 등은 필요 이상으로 많은 공간을 점유하는 수가 있다. 실제로는 10X10 정도만 사용되어도 100X100 으로 선언될 수 있다.
- 프로그램 내의 어떤 옵션이나 기능들은 거의 사용되지 않는다.
만약 프로그램의 일부분만 메모리에 올려놓고 실행할 수 있다면 다음과 같은 많은 이점이 있다.
- 프로그램은 물리 메모리 크기에 의해 더는 제약받지 않게 된다. 사용자들은 매우 큰 가상 주소 공간을 가정하고 프로그램을 만들 수 있으므로, 프로그래밍 작업이 간단해진다.
- 각 프로그램이 더 작은 메모리를 차지하므로 더 많은 프로그램을 동시에 수행할 수 있게 된다.
이에 따라 응답 시간(response time)은 늘어나지 않으면서도 CPU 이용률(utilization)과 처리율(throughput)이 높아진다. - 프로그램을 메모리에 올리고 스왑(swap)하는 데 필요한 I/O 횟수가 줄어들기 때문에 프로그램들이 보다 빨리 실행된다.
가상 메모리는 실제의 물리 메모리 개념과 개발자의 가상 메모리 개념을 분리한 것이다.
이렇게 함으로써 얻어지는 장점은 작은 메모리를 가지고도 얼마든지 큰 가상 주소 공간을 프로그래머에게 제공할 수 있다는 점이다.
가상 메모리는 프로그래머가 메모리 크기에 관련한 문제를 염려할 필요 없이 쉽게 프로그램을 작성할 수 있게 해준다.
한 프로세스의 가장 주소 공간은 그 프로세스가 메모리에 저장되는 논리적인 모습을 말한다.
일반적으로 위 그림과 같이 특정 가상 주소(보통 0번지)에서 시작하여 연속적인 공간을 차지한다.
물리메모리는 페이지 프레임들로 구성되며 프로세스에 할당된 페이지 프레임들이 실제적으로는 연속된 것들이 아닐 수 있다. 물리적인 페이지 프레임을 가상 페이지로 매핑하는 것은 MMU에 달려있다.
위 그림을 보면 힙은 동적 할당 메모리를 사용함에 따라 주소 공간상에서 위쪽으로 확장된다.
비슷한 방식으로 스택은 함수 호출을 거듭함에 따라 주소 공간상에서 아래쪽으로 확장된다.
힙과 스택 사이의 공백도 가상 주소 공간의 일부이지만, 힙 또는 스택이 확장되어야만 실제 물리 페이지를 요구하게 될 것이다.
공백을 포함하는 가장 주소 공간을 sparse 주소 공간이라고 한다.
가상 메모리를 물리 메모리로부터 분리해주는 것 외에 가상 메모리는 페이지 공유를 통해 파일이나 메모리가 둘 또는 그 이상의 프로세스들에 의해 공유되는 것을 가능하게 해준다.

프로세스들이 메모리를 공유할 수 있다.
프로세스간의 통신 방법 중 하나로 공유 메모리 방식이 있는데, 가상 메모리는 한 프로세스가 다른 프로세스와 공유할 수 있는 영역을 만들 수 있도록 해 준다. 이 영역을 공유하고 있는 프로세스들에는 각자 자신의 주소 공간상에 있는 것처럼 보이지만 실제 물리 메모리는 위 그림처럼 공유되고 있다.
요구 페이징을 통한 가상 메모리 구현
현재 필요한 페이지만 물리 메모리에 적재하는 기법을 요구 페이징 이라고 하며 가상 메모리 시스템에서 일반적으로 사용된다. 따라서 접근되지 않은 페이지는 물리 메모리로 적재되지 않는다.
요구 페이징 시스템은 프로세스가 보조 메모리에 상주하는 스와핑을 사용하는 페이징 시스템과 유사하다.
요구 페이징의 기본 개념은 필요할 때만 페이지를 메모리에 적재하는 것이다. 결과적으로 프로세스가 실행되는 동안 일부 페이지는 메모리에 있고 일부는 보조저장장치에 있다. 따라서 이 둘을 구별하기 위해 어떤 형태로든 하드웨어 지원이 필요하다.
유효-무효 비트 기법이 여기에 적용될 수 있다. 이 비트가 유효(valid)하다고 설정되면 해당 페이지가 메모리에 있다는 의미이고, 무효(invalid)하다고 설정되면 해당 페이지가 유효하지 않거나 유효하지만 보조저장장치에 존재한다는 것을 의미한다.
메모리에 올라오는 페이지에 대해서는 유효로 설정하며, 현재 메모리에 올라와 있지 않은 페이지의 페이지 테이블 항목은 무효로 설정하기만 한다.
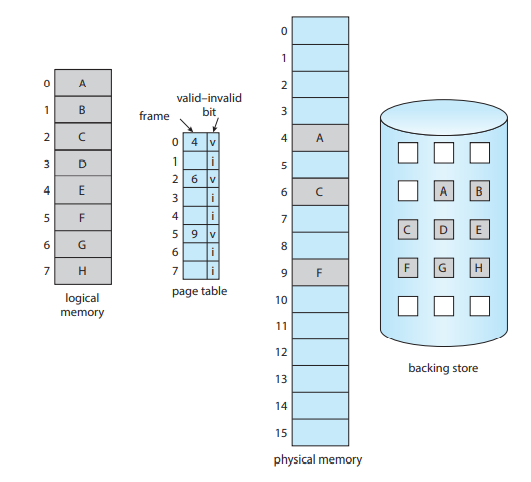
위 그림은 이러한 상황을 나타낸다.
어떤 페이지를 무효로 설정하는 것은 그 페이지를 접근하기 전까지는 어떠한 영향도 끼치지 않는다.
프로세스가 메모리에 올라와 있지 않은 페이지에 접근하려고 하면 어떠한 일이 발생할까?
이때는 페이지 테이블 항목이 무효로 설정되어 있으므로 페이지 폴트 트랩을 발생시킨다.
페이징 하드웨어(MMU)는 페이지 테이블을 이용한 주소 변환 과정에서 무효 비트를 발견하고 운영체제에 트랩을 건다.
이 트랩은 운영체제가 필요한 페이지를 적재하는 데 실패했기 때문에 발생한 결과이다.
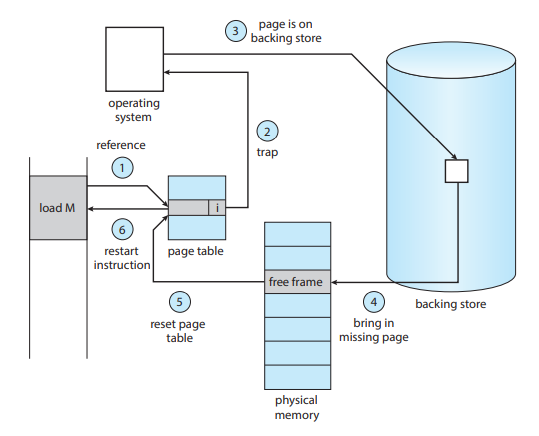
페이지 폴트를 처리하는 과정(간략)
- 프로세스에 대한 내부 테이블을 검사해서 그 메모리 참조가 유효/무효 인지를 알아낸다.
- 만약 무효한 페이지에 대한 참조라면 그 프로세스는 중단된다.
만약 유효한 참조인데 페이지가 아직 메모리에 올라오지 않았다면, 보조저장장치로부터 가져와야 한다. - 물리 메모리의 빈 공간, 즉 가용 프레임을 찾는다.
- 새로 할당된 프레임으로 해당 페이지를 읽어 들이도록(보조저장장치로부터) 요청한다.
- 보조저장장치 읽기가 끝나면, 이 페이지가 이제는 물리 메모리에 있다는 것을 알리기 위해 페이지 테이블을 갱신하며, 프로세스가 유지하고 있는 내부 테이블을 수정한다.
- 트랩에 의해 중단되었던 명령어를 다시 수행한다.
이제 프로세스는 마치 그 페이지가 항상 메모리에 있었던 것처럼 해당 페이지에 접근할 수 있다.
페이지 폴트를 처리하는 과정(상세)
- 운영체제에 트랩을 요청한다.
- 레지스터들과 프로세스 상태를 저장한다.
- 인터럽트 원인이 페이지 폴트임을 알아낸다.
- 페이지 참조가 유효한 것인지 확인하고, 보조저장장치에 있는 페이지의 위치를 알아낸다.
- 새로 할당된 프레임으로 해당 페이지를 읽어 들이도록(보조저장장치로부터) 요청한다.
- 읽기 차례가 돌아오기까지 대기 큐에서 기다린다.
- 디스크에서 찾는 시간과 회전 지연 시간 동안 기다린다.
- 가용 프레임으로 페이지 전송을 시작한다.
- 기다리는 동안에 CPU 코어는 다른 사용자에게 할당된다.
- 저장장치가 다 읽었다고 인터럽트를 건다(I/O완료).
- 다른 프로세스의 레지스터들과 프로세스 상태를 저장한다.(6단계가 실행되었을 경우)
- 인터럽트가 보조저장장치로부터 왔다는 것을 알아낸다.
- 새 페이지가 메모리로 올라왔다는 것을 페이지 테이블과 다른 테이블들에 기록한다.
- CPU 코어가 자기 차례로 오기까지 다시 기다린다.
- CPU 를 할당받으면 위에서 저장시켜 두었던 레지스터들, 프로세스 상태, 새로운 페이지 테이블을 복원시키고 인터럽트 되었던 명령어를 다시 실행한다.
극단적인 경우에는 메모리에 페이지가 하나도 안 올라와 있는 상태에서도 프로세스를 실행시킬 수 있다.
운영체제에서 명령 포인터의 값을 프로세스의 첫 명령으로 설정하는 순간, 이 명령이 메모리에 존재하지 않는 페이지에 있으므로, 페이지 폴트를 발생시킨다.
페이지가 적재되고 나면 프로세스는 수행을 계속하는데 프로세스가 사용하는 모든 페이지가 메모리에 올라올 때까지 필요할 때마다 페이지 폴트가 발생한다.
이것을 순수 요구 페이징 이라고 한다.
즉, 어떤 페이지가 필요해지기 전에는 결코 그 페이지를 메모리로 적재하지 않는 방법이다.
가용 프레임 리스트란?
페이지 폴트가 발생하면 운영체제는 요청된 페이지를 보조저장장치에서 메인 메모리로 가져와야 한다.
페이지 폴트를 해결하기 위해 대부분의 운영체제는 이러한 요청을 충족시키기 위해 사용하기 위한 가용 프레임의 풀인 가용 프레임 리스트를 유지한다.

프로세스의 스택 또는 힙 세그먼트가 확장될 때도 가용 프레임이 할당되어야 한다.
운영체제는 일반적으로 Zero-fill-on-demand 라는 기법을 사용하여 가용 프레임을 할당한다.
Zero-fill-on-demand 프레임은 할당되기 전에 0으로 모두 채워져 이전 내용이 지워진다.
시스템이 시작되면 모든 가용 메모리가 가용 프레임 리스트에 넣어진다.
가용 프레임이 요청되면(ex. 요구 페이징을 통해) 가용 프레임 리스트의 크기가 줄어든다.
Copy-on-Write
[XV-6 운영체제] Copy-on-Write #1
Copy-on-Write가 어떤 기능을 하는지 알아보자 Copy on Write는 기본적으로 forks 기능과 관련이 있다. forks는 parent process를 이용해서 child process를 만들어 내는 것으로 볼 수 있다. (기본적으로 복제를..
hyeo-noo.tistory.com
페이지 교체 알고리즘
[운영체제] Page Replacement Policy (페이지 교체 알고리즘)
[운영체제] Swapping #1 메모리 swapping에 대해서 알아보자 Swap : 필요한 주소공간 전체를 메모리에 올려 두는것이 아니라 그때 그때 필요한 것들만 메모리에 올리고, 필요없어지면 하드디스크로 내
hyeo-noo.tistory.com
프레임의 할당
128개의 프레임을 가지는 간단한 시스템을 고려해 보자.
여기서 운영체제가 35개를 차지하고 나면 나머지 93개의 프레임이 사용자 프로세스를 위해 남는다.
순수 요구 페이징 기법에서는 처음에 93개의 프레임 모두가 가용 프레임 리스트에 들어가게 된다.
사용자 프로세스들이 실행을 시작하면 일련의 페이지 폴트를 발생시키게 된다.
처음부터 93번까지의 페이지 폴트는 가용 페이지 리스트에서 가용 페이지를 사용하게 한다.
이제 가용 페이지가 없어지면, 94번째 페이지 폴트 부터는 이미 사용한 93개의 페이지 중에서 하나를 선택해 페이지 교체를 해야 한다. (프로세스가 종료되면 93개의 프레임은 다시 가용 프레임 리스트로 반환된다.)
최소로 할당해야 할 프레임의 수
메모리 할당에는 다양한 제한이 존재한다.
예를 들어,
1. 가용 프레임의 수보다 더 많이 할당할 수는 없다.
2. 최소한 몇 페이지는 할당해야만 한다.
두 번째 제한에 대해 좀 더 자세히 살펴보자.
최소한의 프레임을 할당해야만 하는 한 가지 이유는 성능 때문이다.
각 프로세스에 할당되는 프레임 수가 줄어들면 페이지 폴트율을 증가하고 프로세스 실행은 늦어지게 된다. 또한 명령어 수행이 완료되기 전에 페이지 폴트가 발생하면 그 명령어를 처음부터 재실행해야 한다.
따라서 하나의 명령어가 참조하는 모든 페이지는 동시에 메모리에 올라와 있어야 그 명령어의 수행이 끝날 수가 있게 된다.
예를 들어, 모든 메모리 참조 명령어가 단 하나의 주소만을 갖는 기계가 있다. 이 경우 명령어에 의한 메모리 접근을 위해 최소한 하나의 프레임이 필요하다.
여기에 간접 주소 지정이 가능한 경우
-> 프레임 16에 있는 load 명령이 프레임 23에 대한 간접 참조를 담고 있는 프레임 0에 있는 주소를 가리키는 것
이 경우에는 프로세스당 최소 3개의 프레임이 필요하다.
할당 알고리즘
균등 할당
93개의 가용 프레임이 존재하고, 5개의 프로세스가 있으면 각 프로세스는 18개씩의 프레임을 받고 나머지는 가용 프레임 버퍼 저장소로 사용한다.
n개의 프로세스에 m개의 프레임을 분할하는 가장 쉬운 방법은 모두에 같은 몫 m/n 프레임씩 주는 것이다.
비례 할당
학생이 만든 10KB의 작은 프로세스와 127KB의 데이터베이스 프로그램이 62개의 가용 프레임(프레임당 1KB)을 갖는 시스템에서 수행되고 있다면, 각각 31프레임씩 할당받는 것은 좋은 방법이 아니다. 학생 프로세스는 10개의 프레임만 사용할 것이므로 21프레임이 낭비되기 때문이다.
대신에 프로세스의 크기 비율에 맞추어 프레임을 할당하는 비례 할당 방법을 사용할 수 있다.
프로세스 pi의 크기를 si라고 하면
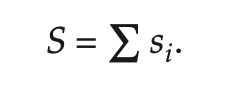
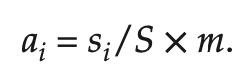
각 프로세스당 할당 받게되는 프레임 ai는 위 식을 통해 구할 수 있다.
균등 할당과 비례 할당은 모두 프로세스의 우선순위를 고려하지 않는다.
우선순위가 낮은 프로세스에 손실을 주더라도 우선순위가 높은 프로세스에 더 많은 기억장소를 할당하여 빨리 수행해야할 수도 있다.
이때, 비례 할당 방법을 사용하면서 프레임 비율을 프로세스의 크기가 아닌 우선순위를 사용하여 또는 크기와 우선순위의 조합을 사용하여 결정할 수 있다.
전역 / 지역 할당
- 전역 교체 : 프로세스가 교체할 프레임을 다른 프로세스에 속한 프레임을 포함한 모든 프레임을 대상으로 찾는 경우.
- 지역 교체 : 각 프로세스가 자신에게 할당된 프레임 중에서만 교체될 프레임을 선택하는 경우.
전역 교체 방법은 프로세스의 메모리에 있는 페이지 집합이 현재 프로세스의 페이징 동작뿐만 아니라 다른 프로세스의 페이징 동작에도 영향을 받는다. 따라서 동일한 프로세스도 외부 환경에 영향을 받아서 실행시간이 매번 달라질 수 있다.
반면에 지역 교체 방법은 유일하게 그 프로세스의 페이징 동작에만 영향을 받기 때문에 실행시간에 대한 영향은 받지 않는다.
그러나 잘 안쓰는 페이지 프레임이 있다면 그것을 그대로 낭비할 수 있다는 단점이 있다.
일반적으로 전역 교체가 지역 교체 알고리즘보다 더 좋은 시스템 성능을 보인다.
전역 교체를 사용할 때 사용할 수 있는 전략
- 메모리가 꽉 찰 때까지 기다렸다가 가득 차게 되면 replace를 수행한다.
가용 프레임이 없으면 가용 프레임을 만들기 위해서 현재 메모리의 일부 페이지를 스왑 공간으로 내려 보내야 한다.
- 메모리에서 내보낼 page를 읽고 들여올 page를 읽는 작업이 한 번씩 수행된다.
- 때문에 기존에는 메모리에 들일 page를 읽는 작업만 수행하면 되었지만 이러한 방식은 메모리를 총 2번 읽기 때문에 느리고 비효율적이다.
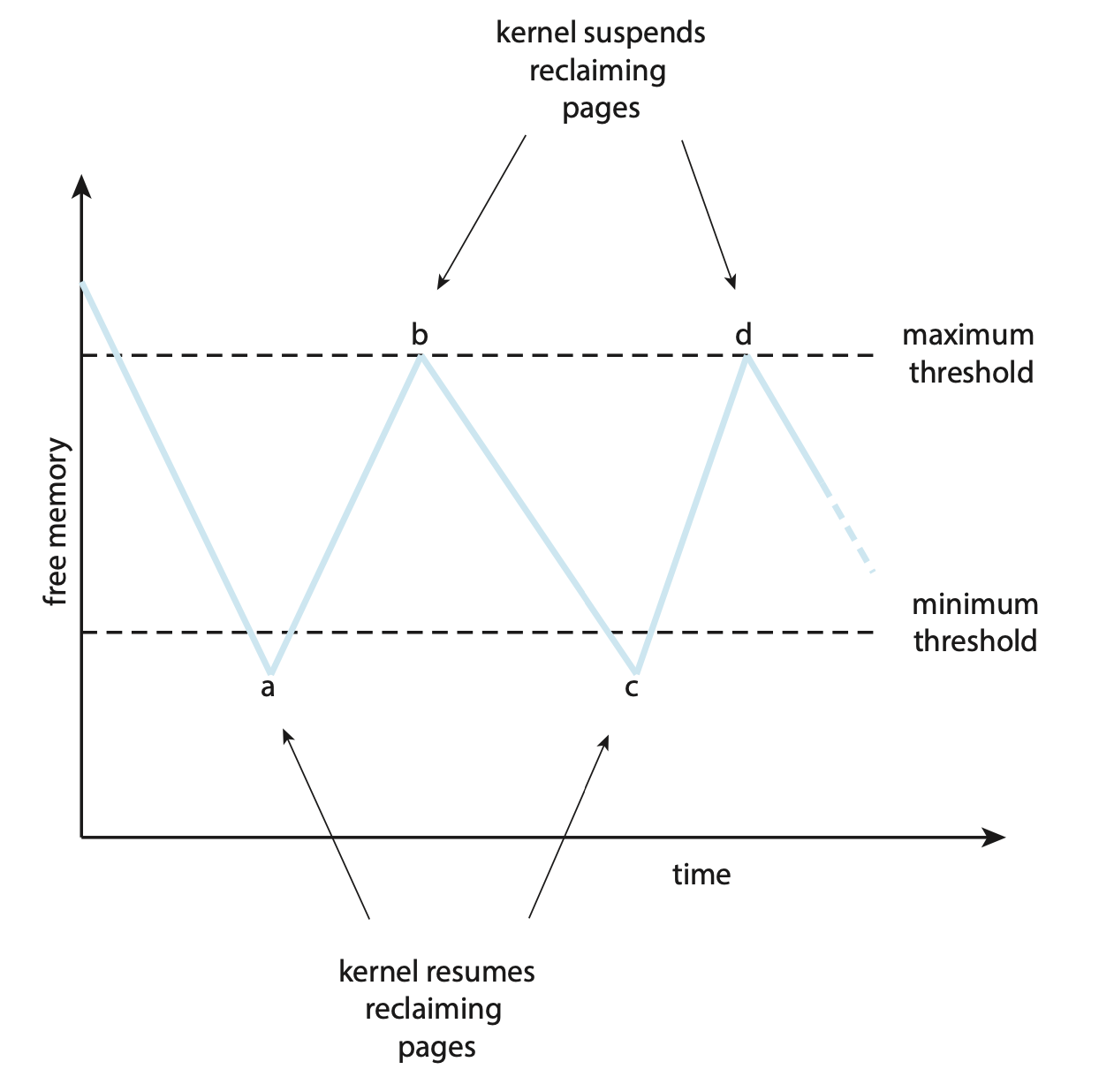
- Swap Daemon, Page Daemon 방식 : 항상 일정 공간을 메모리에 남겨두는 방식
- LW pages : page replace를 시작해야 할 기준점.
- HW pages : page replace를 마무리할 기준점
- physical memory의 free page숫자가 LW pages보다 작아지게 되면 replacement를 수행한다.
- 이왕 replace를 시작했으니 replacement를 계속 수행한다. free page의 숫자가 HW pages와 같아질 때까지
이러한 루틴을 수행하는 커널을 리퍼(reaper)라고 한다.
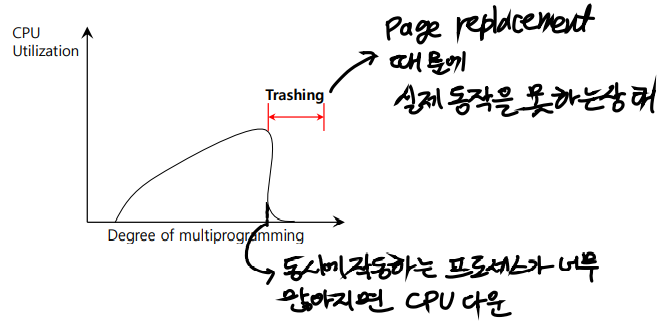
Thrashing
현재 사용중인 process가 너무 많아서 작업 집합의 페이지를 지원하는 데 필요한 최소 프레임도 없는 경우, 현재 프로세스는 곧바로 페이지 폴트를 일으킨다.
이때 page replacement가 발생하지만 이미 활발하게 사용되는 페이지들 만으로 이루어져 있으므로
어떤 페이지가 교체되든 바로 다시 필요해질 것이다.
결과적으로 페이지 폴트는 계속해서 발생하고 교체된 페이지는 얼마 지나지 않아 다시 읽어올 필요가 생기게 된다.
이러한 과도한 페이징 작업을 스래싱이라고 부른다.
어떤 프로세스가 실제 실행보다 더 많은 시간을 페이징에 사용하고 있으면 스래싱이 발생했다고 한다.
그래서 실제 동작을 전혀 못하는 상태일때 강제로 process를 삭제하게 된다.
스래싱의 영향을 제한하기 위해서는 지역 교체 알고리즘 또는 우선순위 교체 알고리즘을 사용해서 스래싱의 영향을 제한해야 한다.
따라서 각 프로세스가 필요로 하는 최소한의 프레임 개수를 알 수 있다면 스래싱 현상을 방지할 수 있을 것이다.
프로세스 실행의 지역성 모델(locality model)을 기반으로 알 수 있다.
지역성 모델이란?
프로세스가 실행될 때는 항상 어떤 특정한 지역(페이지 집합)에서만 메모리를 집중적으로 참조함을 의미한다.
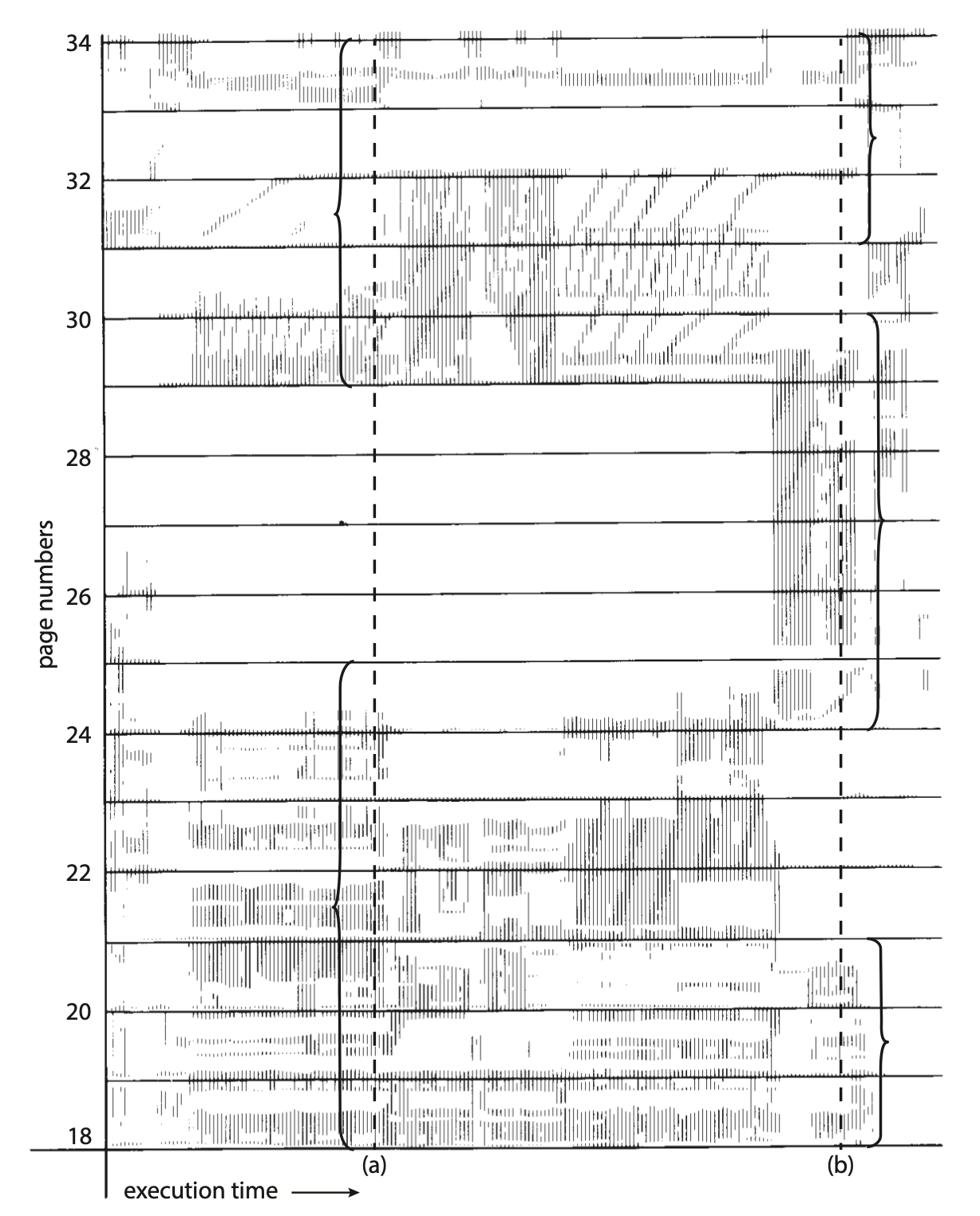
위 그림에서 (a)시간에는 [18~24, 29~33] 번째 페이지들을 참조하고, (b)시간에는 [18~20, 24~33] 번째 페이지들을 참조한다.
지역성 모델은 지금까지 알아본 캐싱 기법의 기본 원리이기도 하다.
작업 집합 모델이란?
한 프로세스가 최근 delta개의 페이지를 참조했다면 그 안에 들어있는 서로 다른 페이지들의 집합을 작업 집합이라고 부른다.
너비가 delta인 창(window)를 움직인다고 생각할 수 있다.
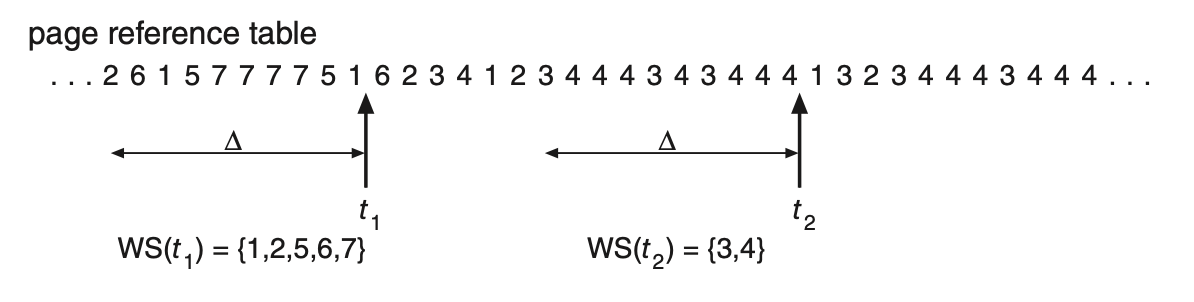
만약 delta=10 이라고 가정하면 시간 t1 에서의 작업 집합은 {1,2,5,6,7}이 되고, 시간 t2에서는 {3,4}가 된다.
작업 집합의 정확도는 delta의 선택에 따라 좌우된다.
만약 delta값이 너무 작으면 전체 지역을 포함하지 못할 것이고, delta값이 너무 크면 여러 지역성을 과도하게 수용할 것이다.
일단 delta값을 적절하게 설정하면 운영체제는 각 프로세스에 작업 집합 크기(delta)에 맞는 충분한 프레임을 할당한다.
그러다 실행중인 프로세스의 수가 너무 많아져서 sum(delta)가 전체 메모리의 크기보다 커지게 되면,
프로세스를 하나 선택해서 그 프로세스의 페이지들을 빼앗고, 연기시키고, 프레임들을 다른 프로세스에 주게 된다.
그리고 연기된 프로세스는 나중에 재개될 수 있다.
작업 집합과 페이지 폴트율
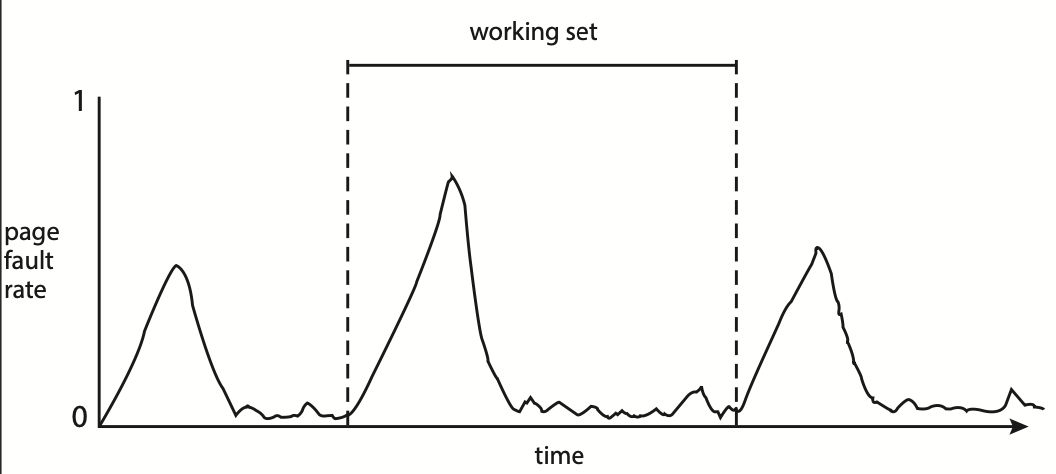
프로세스의 작업 집합과 페이지 폴트율 사이에는 직접적인 연관이 있다.
보통 데이터와 코드에 대한 참조는 시간의 흐름에 따라 한 지역에서 다른 지역으로 옮겨가게 된다.
프로세스의 작업 집합을 수용할 수 있는 충분한 메모리가 있으면, 페이지 폴트율을 시간이 지남에 따라 고점과 저점 사이를 오르내리게 된다.
페이지 폴트율의 고점은 새로운 지역으로 들어가 요구 페이징이 시작되는 경우에 발생한다.
일단 새로운 지역의 작업 집합이 메모리에 올라오고나면 폴트율을 낮아진다.
새로운 작업 집합으로 이동할 때 다시 폴트율을 높아지게 된다.
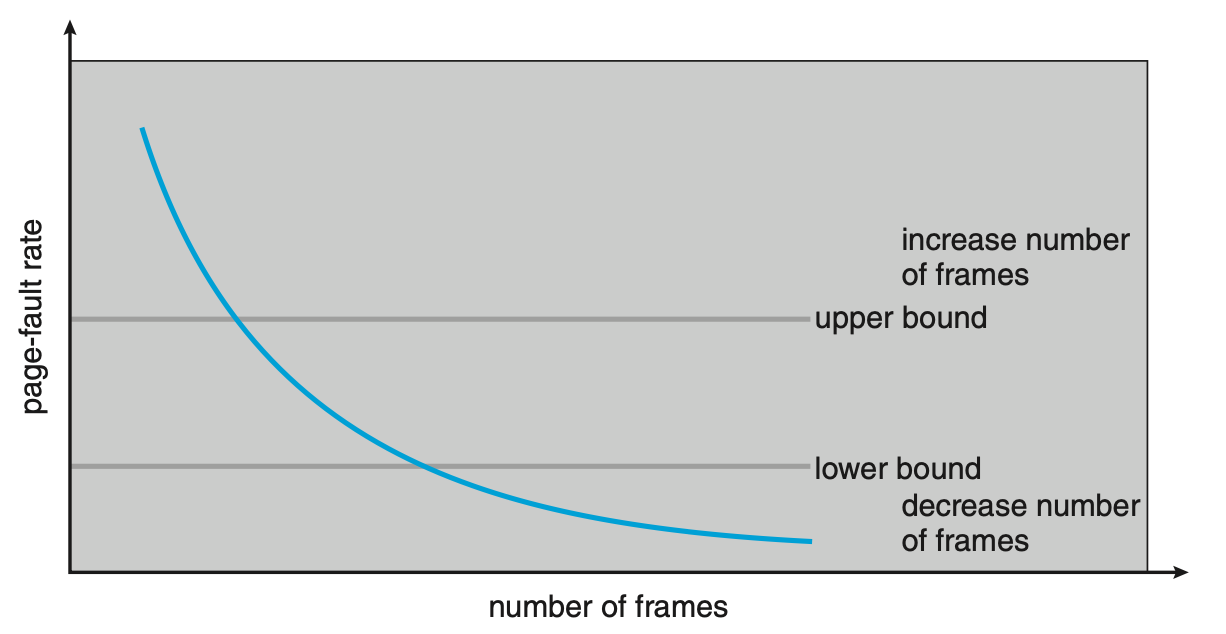
스래싱을 쉽게 생각하면 페이지 폴트율이 너무 높은 경우를 의미한다.
그렇다고 페이지 폴트율이 너무 낮은 경우는 프로세스가 너무 많은 프레임을 할당받았다는 것을 의미할 수도 있다.
따라서 페이지 폴트율의 상한과 하한을 정해놓고, 만약 페이지 폴트율이 상한을 넘으면 그 프로세스에 프레임을 더 할당해 주고, 하한보다 낮아지면 그 프로세스의 프레임 수를 줄인다.
'CS > OS' 카테고리의 다른 글
| [운영체제] Ch9. 메인 메모리 (0) | 2022.03.10 |
|---|---|
| [운영체제] Ch7. 고전적인 동기화 문제들 (0) | 2022.03.04 |
| [운영체제] Ch6. 동기화 도구들 (0) | 2022.02.22 |
| [운영체제] Ch5. CPU 스케줄링 (0) | 2022.02.18 |
| [운영체제] Ch4. 스레드와 병행성 (0) | 2022.02.11 |