![[컴퓨터 구조] ILP & Superscalar](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fcst39o%2Fbtq6w6fkaZd%2FGWEJLNIcPQztcLBwpFAFXk%2Fimg.png)
ILP : Instrction Level Parallelism
ILP의 2가지 방법
Superscalar : 1 Cycle 동안에 서로 다른 독립적인 2개의 연산을 동시에 수행하는 기술이다.

Superpipeline : 한 클럭을 2개로 나누고, 나누어진 클럭에서 각각 서로 다른 연산을 수행하는 기술이다.

ILP실행의 한계점
1. True Data Dependency

ADD의 r1과 MOVE의 r1은 서로 의존적이다. pipeline에서의 타이밍을 맞추지 못하면
MOVE에서 잘못된 r1값(add가 되기 전의 r1)을 받아서 틀린 연산 결과를 낼 수 있다.
2. Procedural Dependancy
- if(~) ...
- else(~) ...
위와 같은 branch가 있을 때 branch이전과 branch 이후는 상황이 많이 다를 것이다.
따라서 branch의 이전과 이후를 병렬로 진행하는 것은 의미가 없다.
3. Resource Conflict
두 개 이상의 명령어가 같은 자원(레지스터)을 바라보기 때문에 충돌이 일어나는 상황

2번째 줄의 Data Dependency는 i0의 결과가 나온 후 i2에서 올바른 값을 가지고 명령을 수행한다.
3번째 줄의 Procedural Dependency는 브랜치 전 후의 명령을 동시에 superscalar방식으로 수행할 수 없다.
4번째 줄의 Resource Conflit는 Execution resource가 하나밖에 없으므로 서로 경쟁을 해서 가져간다.
Design Issues
Instruction level parallelism
명령어만으로 병렬 처리가 가능하다 : 실행 유닛이 2개 이상이고, 디코더, fetch 모두 2개 이상일 때 가능하다
만약 연속으로 된 명령어가 독립적이라면 실행은 overlap(2개가 동시에 수행) 될 수 있다.
Instruction Issue Policy : 명령어를 실행시키기 위해서 준비를 하는 과정
정책의 이유
- 실행을 할 수 있는 엔진이 여러 개다
- 최적의 알고리즘을 위해서, 의도한 결과를 얻기 위해서
고려할 요소들

- 명령어를 어떤 순서로 가지고 오는지
- 어떤 순서로 실행되는지(중요)
- 명령에 의한 레지스터 메모리 변화
Superscalar Instruction Issue Policies
실행 엔진이 여러 개인 걸 극대화시켜서 성능을 올려야 한다
- In-order issue with in-order completion : 어떤 프로그램이 있으면 원래 순서를 유지해서 CPU에 준다 , CPU는 받은 순서대로 실행을 시켜서 끝을 낸다.
- In-order issue with out-of-order completion : 원래 순서대로 받고, 순서를 바꿔서 효율적으로 실행시킨다
- Out-of-order issue with out-of-order completion : 처음부터 순서 바꿔서 받고 실행도 순서를 바꾼다.
In-order issue with in-order completion
- 그렇게 복잡하지도 않고 그렇게 효율적이지도 않다



I3/I4(둘 다 부동 소수점 연산기를 사용), I5/I6(둘 다 2번 정수 연산기 사용) : 동시 처리 불가 (Resource Conflict)
I5 / I4 : 동시 실행 불가 (True data dependency)
결국 Write를 보면 Issuing을 한 순서대로 출력이 됨을 알 수 있다.
In-order issue with out-of-order completion
True Data Dependency는 결과물이 나올 때까지 해당 결과를 사용하는 명령어를 decoding 해서는 안된다는 뜻이다.
여기선 'Output dependency'라는 개념이 중요하다.

만약 out-of-order를 적용해서
I1보다 I3를 먼저 실행한다면 R3이 R5+1로 바뀔 것이다.
그리고 I1을 실행하면 R3는 결국 R5 + 1 + R3 + R5가 될 것이고, 이는 I1이 원하는 결과(R3 + R5)와는 매우 다른 결과를 반환할 것이다. 이를 Output dependency라고 한다.
만약 이때 결과가 바뀌지 않으면 먼저 실행을 해도 된다. (Out-of-order completion)
하지만 위 그림의 코드는 실행 순서를 바꾸면 안 된다.
즉 Output dependency 가 있을 때는 Out-of-order completion 정책을 사용하면 안 된다.
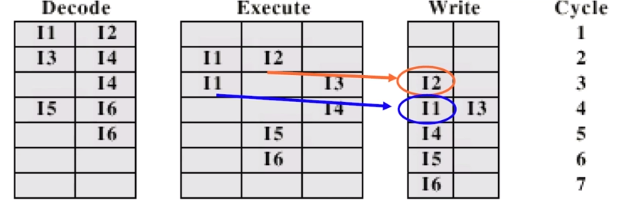
이전에서는 I1과 I2 가 같이 Issuing 되었으므로 같이 Write-back을 했다.
하지만 여기서는 data dependency 가 없다고 가정했기 때문에
이미 실행이 끝난 I2의 결과를 3 Cycle에서 Write-back 한다.

Out-of-order issue with out-of-order completion
Issuing순서도 바꾸는 경우


- Decode 단계와 Execute 단계를 분리


추가적으로 고려할 요소
1. Antidependency
True dependency와 반대의 개념이다.
또 Write-after-read dependency라고도 한다.

그림을 위에서 아래로 실행하면 문제가 없다.
만약 이 순서를 뒤 바꾸면 문제가 생기기 때문에 먼저 읽어야 한다는 정책도 있는 것이다.
2. Register Renaming
Antidependencies와 Output dependencies를 해결할 수 있다.
-> 필요할 때 레지스터를 추가하라는 의미이다.
예를 들어 R3 레지스터가 여러 개 있다고 생각하고, 이를 필요할 때 사용하라는 의미이다.
기존 코드는 I1부터 I4까지 순서대로 실행을 시켜야 오류가 없기 때문에 Superscalar방식을 적용할 수 없었다.

기존 코드에선 R3 가 하나밖에 없는 것처럼 보이지만, Renaming 기법을 사용하면 세 개를 사용한다

위와 같은 방식으로 Antidependencies와 Output dependencies를 해결할 수 있다.

window를 통해 명령어를 매우 빠르게 분석해서 Issuing 순서를 바꾼다.
'CS > Computer Architecture' 카테고리의 다른 글
| [컴퓨터 구조] 컴퓨터 시스템 개요 (2) | 2021.11.24 |
|---|---|
| [컴퓨터 구조] Addressing Mode (0) | 2021.06.12 |
| [컴퓨터 구조] Instruction Set (0) | 2021.06.12 |
| [컴퓨터 구조] Control Unit (0) | 2021.06.06 |
| [컴퓨터 구조] RISC (feat. CISC) (0) | 2021.06.03 |