![[컴퓨터 구조] 기억 장치 기본](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fcgox9B%2Fbtro1288zdZ%2FErar0AstcFiLcLWKMiLbVk%2Fimg.png)
기억장치의 데이터 엑세스 유형
순차적 엑세스
기억장치에 저장된 정보들을 처음부터 순서대로 엑세스한다.
자기 테이프 저장장치가 이 방식을 이용한다. 카세트를 떠올리면 이해가 편하다.
특징으로는, 임의의 위치에 저장된 특정 정보를 읽기 위해서 그 위치에 도달할 때까지 앞부분의 테이프를 모두 통과해야 한다. 따라서 정보가 저장된 위치에 따라 엑세스 시간이 달라진다.
직접 엑세스
읽기/쓰기 장치가 각 레코드의 근처로 직접 이동한 후에 순차적 검색을 통해 최종 위치에 도달한다. CD, DVD 가 사용하는 방식이다.
CD를 읽는 팔이 움직여서 데이터가 있는 트랙으로 이동한다.
그리고 CD가 특정 방향으로 회전하며 데이터가 있는 섹터로 이동한다.
따라서 현재 위치에서 원하는 섹터에 도달하기 위한 엑세스 시간이 가변적이다.
임의 엑세스
기억장치 내의 모든 저장 장소들은 고유의 주소를 가지고 있으며, 별도의 읽기/쓰기 회로를 가지고 있다.
어떤 위치든 임의로 선택될 수 있고, 직접 주소지정을 할 수 있고, 엑세스될 수 있다.
CPU의 레지스터, CPU Cache, 메인메모리, SSD 등이 사용하는 방식이다.
연관 엑세스
임의 엑세스의 변형이다.
각 기억장소에는 키(key)값에 해당하는 비트들이 데이터와 함께 저장되어 있다.
엑세스 요청에는 데이터의 주소 대신, 원하는 비트 패턴이 포함되어있는데, 그 비트들과 각 기억장소의 키 비트들을 비교하여, 일치하는 기억장소의 데이터가 읽혀져 출력된다.
키값의 비교에 걸리는 시간은 항상 일정하다.
일반적으로 모든 기억 장소의 키값들을 동시에 비교할 수 있는 하드웨어를 포함한다.
따라서 회로가 매우 복잡하고 비싸다.
기억장치의 주요 특성
1. 용량
기억장치에서 용량을 나타내는 단위는 바이트(Byte) 또는 단어(word)이다.
일반적으로 단어의 길이는 8, 16, 32, 64비트인데, 단어의 길이는 CPU가 실행할 명령어의 길이 혹은 내부 연산에서 한 번에 처리할 수 있는 데이터 비트의 수와 같다.
CPU가 한 번의 기억장치 엑세스에 의해 읽거나 쓸 수 있는 비트 수를 전송 단위라고 한다.
내부 기억장치에 있어서 전송 단위는 기억장치 모듈로 들어가고 나오는 데이터 선? 들의 수와 같다. 데이터 선의 수는 단어 길이와 같거나 작다.
외부 기억장치에서는 데이터가 단어보다 훨씬 더 큰 단위로 전송되기도 한다.
그 단위를 블록(block)이라고 부른다. 대용량 저장장치의 경우에는 블록의 크기가 512바이트 혹은 1KB이다.
그러나 외부 저장장치에 접속되는 데이터 버스의 폭은 8, 16, 32비트이므로 한 블록을 전송하기 위해서는 여러 번의 전송 동작들이 연속적으로 수행되어야 한다.
주소지정 단위란?
각 기억장치 위치에는 고유의 주소가 할당되는데, 각 바이트에 대하여 별도의 주소를 지정할 수도 있고, 각 단어 별로 주소를 지정할 수도 있다.
대부분의 시스템들에서 주소지정 단위가 바이트이지만, 단어 단위로 주소를 지정하는 시스템들도 있다.
CPU에서 처리하는 주소 비트의 수가 A라고 하자.
만약 바이트별로 주소를 지정한다면, 주소가 지정될 수 있는 기억장치의 용량은 N바이트이다.
만약 단어별로 주소를 지정하고, 단어의 크기가 4바이트인 경우, 주소가 지정될 수 있는 기억장치의 용량은 4N바이트이다.
단어별로 주소를 지정하는 방식이 더 많은 용량을 제어할 수 있다.
하지만 바이트단위로 주소를 지정하는 경우에는 필요한 바이트만 별도로 엑세스할 수 있다.
2. 엑세스 속도
엑세스 시간
주소와 읽기/쓰기 신호가 기억장치에 도착하는 순간부터 데이터가 저장되거나 읽혀지는 동작이 완료되는 순간까지의 시간을 말한다.
기억장치 사이클 시간
엑세스 시간과 다음 엑세스를 시작하기 위해 필요한 동작에 걸리는 추가적인 시간을 합한 시간이다.
추가적인 시간이란?
읽기 동작 후에 정보가 소멸되는 저장장치(자기 코어, FRAM)인 경우에 그것을 복원시키는 데 걸리는 시간을 말한다.

데이터 전송률
기억장치로부터 초당 읽혀지거나 쓰여질 수 있는 비트수를 말한다.
전송률 = 용량/시간
계층적 기억장치 시스템
기억장치 법칙
- 엑세스 속도가 높아질수록 비트당 가격도 높아진다.
- 용량이 커질수록, 비트당 가격은 낮아진다.
- 용량이 커질수록, 엑세스 속도는 낮아진다.
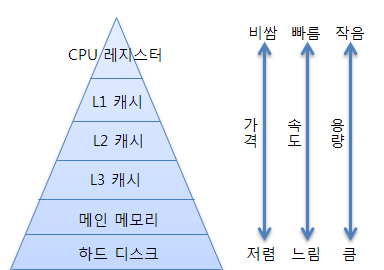
CPU내부에 레지스터, L1캐시, L2캐시, L3캐시가 존재한다.
우리가 아는 RAM이 메인 메모리이다.
우리가 아는 삼성SSD, HDD를 하드 디스크라고 한다.
캐시라는 용어의 개념이 혼동될 수 있다.
레지스터는 CPU의 캐시이다. (CPU는 L1캐시의 내용을 임시저장하기 위해서 레지스터를 캐시로 사용한다.)
L1캐시는 레지스터의 캐시이다.
...
메인 메모리는 L3의 캐시이다.
특정 계층에서 데이터를 반복적으로 사용하기 위해 임시로 저장해 두는 장소를 캐시라고 할 수 있다.
위와 같은 계층 구조를 사용하는 이유는 `지역성의 원리`(principle of locality) 때문이다.
CPU가 엑세스 하는 데이터의 위치는 한정적이다. CPU는 계속 비슷한 곳에 있는 데이터를 요청하게 되고 이를 빠른 저장 장치에 옮겨둔다면 데이터를 매우 효율적으로 읽을 수 있을 것이다.
이를 지역성의 원리라고 하고, 캐시라는 개념이 생기게 된 이유이다.
만약 지역성이 존재하지 않아서 CPU가 계속해서 하드디스크의 다양한 데이터를 요청한다면 이러한 계층구조는 오히려 비효율적일 수 있다.
그런데 위와 같은 일은 일어나지 않는다.
'CS > Computer Architecture' 카테고리의 다른 글
| [컴퓨터 구조] 기억장치 모듈 설계 (0) | 2022.01.05 |
|---|---|
| [컴퓨터 구조] RAM & ROM (0) | 2021.12.30 |
| [컴퓨터 구조] 제어 유니트 (Control Unit) (0) | 2021.12.26 |
| [컴퓨터 구조] 산술 연산(덧셈, 곱셈) (0) | 2021.12.04 |
| [컴퓨터 구조] 산술 연산 (Shift) (2) | 2021.12.01 |