![[컴퓨터 구조] 제어 유니트 (Control Unit)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fcb3p0N%2FbtroSVIEp1P%2FdNCzuvWgDhETXwlGJQM8N0%2Fimg.png)
제어 유니트의 기능
제어 유니트가 수행하는 주요 기능들은 아래와 같다.
- 명령어 코드 해독
- 명령어 실행에 필요한 제어 신호들의 발생
제어 유니트는 컴퓨터 프로그램을 구성하고 있는 명령어들을 해독하고, 그 결과에 따라 명령어 실행에 필요한 동작들을 수행시키기 위한 신호들을 발생하는 장치이다.
같은 말로, 명령어 사이클이 적절히 수행되도록 모든 동작들을 제어하는 장치이다.
명령어 사이클은 다음으로 이루어진다.
- 인출 사이클
- 간접 사이클
- 실행 사이클
- 인터럽트 사이클
각 사이클에서는 여러 개의 마이크로 연산들이 수행된다.
예를 들어, 인출 사이클에서 수행되는 마이크로-연산들을 다시 보면 아래와 같다.

- 프로그램 카운터에 저장되어있는 다음 명령어의 주소를 MAR로 이동시킨다.
- 메모리의 MAR 위치에 있는 데이터를 MBR로 이동시키고, 프로그램 카운터를 1 증가시킨다.
- MBR에 있는 데이터의 해독을 위해 IR로 이동시킨다.
즉, CPU 클록 주기마다 서로 다른 마이크로 연산이 수행되며, 결과적으로 명령어 인출 동작은 세 주기만에 종료된다.
단, 위 예에서 두 번째 주기(t1)에서는 두 개의 마이크로 연산들이 동시에 수행된다.
용어 정리
각 마이크로 연산이 실제 수행되기 위해서는 2진 비트들로 표현되어야 하는데, 그와 같이 비트들로 이루어진 각 단어를 마이크로 명령어 혹은 제어 단어라고 부른다. 그리고 마이크로 명령어들의 집합을 마이크로 프로그램이라고 한다.
마이크로 명령어들은 명령어 인출과 같은 CPU의 특정 기능을 위하여 그룹 단위로 작성되는데, 이러한 각 그룹을 루틴이라고 부른다. 결과적으로, 명령어 사이클을 위한 마이크로 프로그램은 인출 사이클 루틴, 간접 사이클 루틴, 그리고 실행 사이클 루틴들로 구성된다. 예를 들어, 모든 명령어들에 공통인 인출 사이클 루틴은 세 개의 마이크로 명령어들로 이루어진다. 실행 사이클 루틴은 각 명령어마다 서로 다르며, 각 루틴의 길이도 명령어에 따라 결정된다.
제어 유니트의 구조

- 명령어 해독기 : IR(Instruction Register)로부터 들어오는 명령어의 연산 코드를 해독하여 해당 연산을 수행하기 위한 루틴의 시작 주소를 결정한다.
- 제어 주소 레지스터(Control Address Register: CAR) : 다음에 실행할 마이크로 명령어의 주소를 저장하는 레지스터이다. 이 주소는 제어 기억장치의 특정 위치를 가리킨다.
- 제어 기억장치(Control Memory): 마이크로 명령어들로 이루어진 마이크로 프로그램을 저장하는 내부 기억장치이다.
- 제어 버퍼 레지스터(Control Buffer Register: CBR): 제어 기억장치로부터 읽힌 마이크로 명령어를 일시적으로 저장하는 레지스터이다.
- 서브루틴 레지스터(SuBroutine Register: SBR): 마이크로 프로그램에서 서브루틴이 호출되는 경우에, 현재의 CAR 내용을 일시적으로 저장하는 레지스터이다.
- 순서 제어 모듈(Sequencing Module): 마이크로 명령어의 실행 순서를 결정하는 회로들의 집합이다.
CPU의 명령어 세트를 설계한다는 것은 다음을 의미한다.
- 명령어들의 종류와 비트 패턴을 정의한다.
- 명령어들의 실행에 필요한 하드웨어를 설계한다.
- 각 명령어를 위한 실행 사이클 루틴을 마이크로 프로그래밍한다.
마이크로 프로그램은 사이클 루틴들의 집합이므로 CPU 설계 단계에서 확정되고, 그 후에는 변하지 않는다.
따라서 마이크로 프로그램을 저장하는 제어 기억장치는 ROM으로 만들어져 CPU 칩 내부에 포함된다.
사이클
명령어 인출 사이클 동안에 명령어 레지스터(IR)로 적재된 명령어 비트들 중에서 연산 코드(op-code) 부분은 제어 유니트의 명령어 해독기로 들어온다. 이 연산 코드가 지정하는 연산을 실행 사이클 동안에 제어 기억장치에 저장된 해당 루틴을 실행함으로써 수행된다. 따라서 명령어 해독기는 연산 코드를 이용하여 제어 기억장치 내 해당 실행 사이클 루틴의 시작 주소를 찾아야 한다. (이 과정을 '명령어 해독'이라고 말한다.) 주소를 찾는 방법 중에는 Mapping을 이용하는 방법이 있다.
Mapping방식에서는 명령어의 연산 코드를 특정 비트 패턴과 혼합시킴으로써 그 연산의 수행에 필요한 실행 사이클 루틴의 시작 주소를 찾아낸다.
매핑 방식(사상 방식)
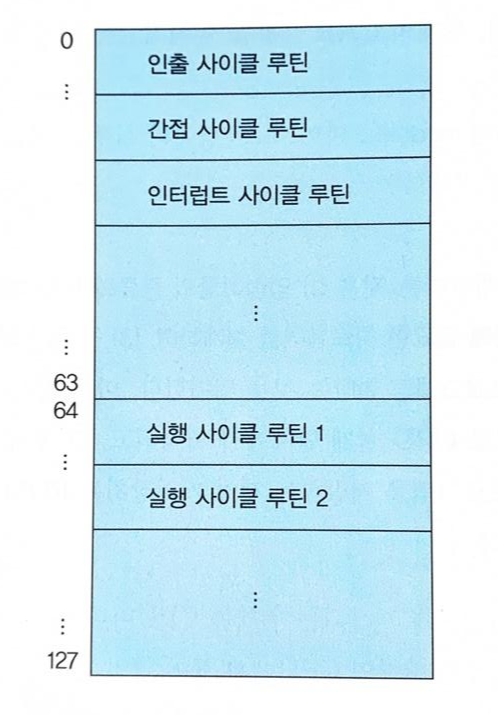
실행 사이클 루틴들이 제어 기억장치의 64번지부터 저장되어 있고, 각 루틴은 최대 4개씩의 마이크로 명령어들로 구성된다고 가정하자.
만약 16비트 길이의 명령어가 4비트의 연산 코드, 1비트의 간접 주소 지정 비트, 11비트의 주소로 구성되어 있다면, 매핑 과정은 다음과 같다.

매핑 함수의 최상위 비트가 '1'이므로, 매핑에 의해 결정되는 주소가 64번지부터 시작할 수 있다.
예를 들어 LOAD 명령어의 연산 코드가 '0001'이라면, 위 그림의 매핑 함수에 의하여 이 연산을 위한 실행 사이클 루틴의 시작 주소를 '1000100', 즉 64 + 4 = 68번지로 결정된다.
위 과정의 명령어 해독 과정을 거친 주소가 CAR로 입력되며, 명령어 실행 사이클이 시작되면 그 위치부터 마이크로 명령어들을 순차적으로 인출하여 수행하게 된다.
여기까지의 궁금증이다. (해결)
궁금증
1. 위 그림의 매핑 함수 1XXXX00 은 어떻게 만들어진 것이며, 만들어지는 기준은 뭘까?
- 연습문제 4.1, 4.2 참고@@
- 뒷 부분에 항상 동일하게 채워진다고 나오는데 다르게 채워지지 않는 이유는??
- 제어 기억장치의 용량과 실행 사이클 루틴이 최대 몇 개의 마이크로 연산들로 구성될지에 따라서 매핑 함수는 다르게 고정된다.
2. 11비트의 주소는 어떤 주소를 의미하는 것일까.
- 분기가 발생하는 경우를 위한 목적지 마이크로 명령어의 주소를 의미한다.
3. LOAD 명령어는 특정 주소에서 데이터를 가져오기 위한 명령어이므로 하나의 주소가 필요하다. 하지만 ADD 같은 명령은 2개의 주소가 필요할 텐데 이런 경우에는 명령어 코드가 어떻게 되는지 궁금하다.
- 바로 아래의 '마이크로 명령어의 형식'에 나와있다.
마이크로 명령어의 형식
제어 기억장치에 저장되는 마이크로 명령어 형식의 한 예를 보면 아래 그림과 같다.

위 그림에서 마이크로 명령어는 길이가 17비트이고, 상단에 표시된 수만큼의 비트들로 이루어지는 다섯 개의 필드들로 구성된다.
이 경우에는 연산 필드가 두 개이므로 두 개의 마이크로 연산들이 동시에 수행될 수 있다.
조건 필드는 분기(if, switch, 함수 실행..)에 사용될 조건 플래그를 지정한다.
분기 필드는 분기의 종류와 다음에 실행할 마이크로 명령어의 주소를 결정하는 방법을 명시해준다.
주소 필드는 분기가 발생하는 경우를 위하여 목적지 마이크로 명령어의 주소를 가지고 있다.
마이크로 연산들에 대한 2진 코드 및 기호의 예
연산 필드 1에 위치할 마이크로 연산들

- 어떤 동작도 수행하지 않는다.
- PC의 주소를 MAR로 이동시킨다.
- IR에 있는 주소를 MAR로 이동시킨다.
- AC값과 MBR 값의 합을 AC에 입력한다.
- 메모리의 MAR위치에 있는 값을 MBR로 이동시킨다.
- MBR에 있는 값을 AC로 이동시킨다.
- MBR에 있는 명령어 해독을 위해 IR로 이동시킨다.
- MBR에 있는 값을 메모리의 MAR위치로 이동시킨다.
연산 필드 2에 위치할 마이크로 연산들

- 어떤 동작도 수행하지 않는다.
- PC를 1 증가시킨다.
- AC에 있는 값을 MBR로 이동시킨다. (ADD의 결과를 메모리에 WRITE 하기 위해 MBR로 이동시키기 위함)
- PC의 주소 값을 MBR로 이동시킨다. (주소 값 저장 또는 연산을 위해 MBR로 이동)
- MBR값을 PC로 이동시킨다. (메모리로부터 읽어온 주소 값을 PC로 이동)
- SP(스택 포인터)를 MAR로 이동시킨다. (스택에 있는 값을 읽어오기 위한 준비 동작)
- AC값에서 MBR에 있는 값을 뺀 결과 값을 AC에 저장한다.
- 명령어 해독이 끝난 값을 PC에 저장한다.
조건 필드의 코드 지정

코드 값 = '00'
현재 마이크로 명령어의 실행이 완료된 다음에는 무조건 분기를 수행한다. 이 경우에 분기될 목적지 마이크로 명령어의 주소를 현재 명령어 형식의 마지막에 있는 주소 필드의 값이 된다. 즉, 주소 필드의 값이 CAR로 적재된다.
코드 값 = '01'
간접 주소 지정 방식을 나타내는 비트의 값에 따라서 분기 여부가 결정된다.
만약 I비트가 1이라면, 간접 사이클 루틴을 호출하여 기억장치로부터 오퍼랜드의 유효 주소를 인출한다.
코드 값 = '10' , '11'
조건 필드의 값이 '10' 혹은 '11'인 경우에는 각각 조건 플래그인 S(부호) 혹은 Z(영) 플래그의 값이 '1'이면 분기가 일어난다. (IF문에서 사용될 듯하다.)
분기 필드의 코드 지정

코드 값 = '00'
JMP : 조건부 점프이다.
만약 조건 필드가 가리키는 조건이 만족되면, 주소 필드(ADF) 값이 CAR로 적재되어서 그 주소의 마이크로 명령어로 점프하게 된다.
그러나 조건이 만족되지 않는다면, 분기는 일어나지 않고 CAR의 내용이 +1 증가되어 다음에 위치한 마이크로 명령어를 실행하게 된다.
코드 값 = '01'
CALL : 조건부 호출이다.
만약 조건이 만족된다면 현재의 CAR내용에 1을 더한 값(다음에 실행된 마이크로 명령어)이 SBR(서브루틴 레지스터)에 저장되고, 주소 필드의 값이 CAR로 적재되어 다음 사이클에서 그 주소의 마이크로 명령어가 실행된다.
그러나 조건이 만족되지 않는다면, 원래 순서대로 다음 마이크로 명령어가 실행된다.
코드 값 = '10'
RET : 복귀
호출되는 루틴의 마지막 마이크로 명령어의 분기 필드에는 반드시 복귀를 나타내는 값인 '10'이 필요하다.
RET이 실행되면 SBR에 저장되어있던 주소가 CAR로 다시 적재됨으로써 호출되기 전의 프로그램 실행 순서로 되돌아가게 된다.
코드 값 = '11'
MAP : 매핑
매핑의 결과로 얻어지는 루틴의 시작 주소가 CAR로 적재되어 그 주소로 분기하게 된다.
즉, 인출 사이클 루틴의 실행이 종료된 다음에, 명령어의 연산 코드에 따라 적절한 실행 사이클 루틴으로 분기되도록 해준다.
CAR의 최상위 비트에는 항상 '1'이 적재되고, 두 번째부터 다섯 번째 비트까지는 4개의 연산 코드 비트들이 들어가며, 마지막 두 비트는 항상 '0'으로 채워진다.
지금까지 설명한 마이크로 명령어 형식을 사용하는 경우에는 각 단어의 길이가 17비트 이므로, 제어 기억장치의 전체 용량은 128 x 17 비트가 된다.
마이크로 프로그래밍
인출 사이클 루틴 : FETCH

제어 기억장치 내부에서 인출 사이클 루틴의 위치가 0번째이므로 'ORG 0'으로 그 위치를 표기하였다.
위 루틴은 3개의 마이크로 명령어들로 구성된다.
첫 번째 사이클에서는 PC의 주소를 MAR로 이동시킨다. 그리고 연산이 끝난 후, 조건 필드 기호 'U'에 따라서 NEXT(다음 마이크로 명령어)로 JMP한다.
두 번째 사이클에서는 2개의 마이크로 연산들이 동시에 수행된다. 메모리의 MAR에 위치한 값을 MBR로 읽어들이고, PC를 1 증가시킨다. 그리고 NEXT로 분기한다.
세 번째 사이클에서는 MBR에 있는 명령어(다음 루틴)를 IR로 이동시킨다. 그리고 매핑을 이용하여 CAR에 실행 사이클 루틴의 시작 주소를 적재함으로써 다음 사이클에서 해당 실행 루틴으로 분기가 일어나게 한다. (인출 사이클이 끝난 후 시작될 다른 임의의 루틴에 대한 주소)
간접 사이클 루틴 : INDRT

어떤 명령어가 간접 주소지정 방식을 사용하는 경우에는 명령어 내의 I 비트가 '1'로 세팅된다. 이 경우에는 실행 사이클의 시작 부분에서 간접 사이클 루틴을 호출하여 기억장치로부터 실제 오퍼랜드 주소를 읽어와야한다.
일반적으로 간접 사이클 루틴은 인출 사이클 루틴의 다음 위치인 4번지부터 저장된다.

간접 사이클 루틴은 IR에 저장되어 있는 명령어의 주소 필드가 가리키는 기억장치 위치로부터 실제 주소를 인출하여 다시 IR의 주소 필드에 적재하는 과정이다.
실행 사이클 루틴

첫 번째 명령어인 NOP는 아무런 연산도 수행하지 않고 PC만 1을 증가시키는 명령어이지만, 특정 목적(?)을 위하여 거의 모든 CPU들의 명령어 세트에 포함되어있다.
LOAD/STORE는 먼저 I 비트를 확인 해서 1이면 간접 사이클 루틴을 호출해서 명령어의 주소를 가져오고, 그렇지 않으면 호출하지 않고 IR(addr)을 바로 사용한다.
LOAD에서는 IR의 주소를 MAR로 옮긴다. 그리고 메모리의 MAR위치에 있는 값을 MBR로 가져온 후, AC로 옮긴다.
STORE는 IR의 주소를 MAR로 옮긴다. 그리고 AC에 있는 값을 MBR로 옮기고, MBR의 값을 메모리의 MAR위치에 저장한다.
ADD는 간접 주소 지정 방식을 사용할 수 없다.
현재 AC값에 더해줄 오퍼랜드의 위치를 MAR에 옮긴다. 그리고 MBR에 메모리의 MAR위치에 있는 값을 적재한다. AC += MBR 을 수행한다.
SUB는 ADD와 동일.
JUMP에서는 인출 사이클 루틴인 FETCH로 JMP되도록 지정함으로써, 각 실행 사이클 루틴의 수행이 종료된 다음에는 인출 사이클부터 다시 시작되도록 한다.
'CS > Computer Architecture' 카테고리의 다른 글
| [컴퓨터 구조] RAM & ROM (0) | 2021.12.30 |
|---|---|
| [컴퓨터 구조] 기억 장치 기본 (0) | 2021.12.29 |
| [컴퓨터 구조] 산술 연산(덧셈, 곱셈) (0) | 2021.12.04 |
| [컴퓨터 구조] 산술 연산 (Shift) (2) | 2021.12.01 |
| [컴퓨터 구조] 컴퓨터 시스템 개요 (2) | 2021.11.24 |